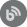

NuGet package is a recommended way to move and deploy projects through DevOps infrastructure for database and other types of projects. It is a Microsoft based solution that is especially convenient when said infrastructure contains different environments like development, QA/testing or production environment.
Another feature that comes with NuGet packages is project versioning and it is a native part of the NuGet file naming principle.
For creating, handling and moving NuGet packages across environments several methods can be used. NuGet package handling is natively supported in Visual Studio as Package Manager extension or a standalone NuGet utility can be used for this purpose and all that is functional in conjunction with NuGet repository solutions.
ApexSQL DevOps toolkit, a SQL database continuous integration (CI) and continuous delivery (CD) solution, in all its instances, also has built-in NuGet package management solution to collect output artifacts for easy review and deploy management.
The Concept
ApexSQL DevOps toolkit consists of configurable steps that are used for creating database CI and CD pipelines. This set of steps implies the ability to build, test, review, provision and deploy SQL database projects.
Every step, when executed, provides some kind of output artifact, whether that is an execution summary, review report or some type of SQL script (e.g. build script, synchronization script, etc.). Outputs are stored in a folder which location can be customized within available options:
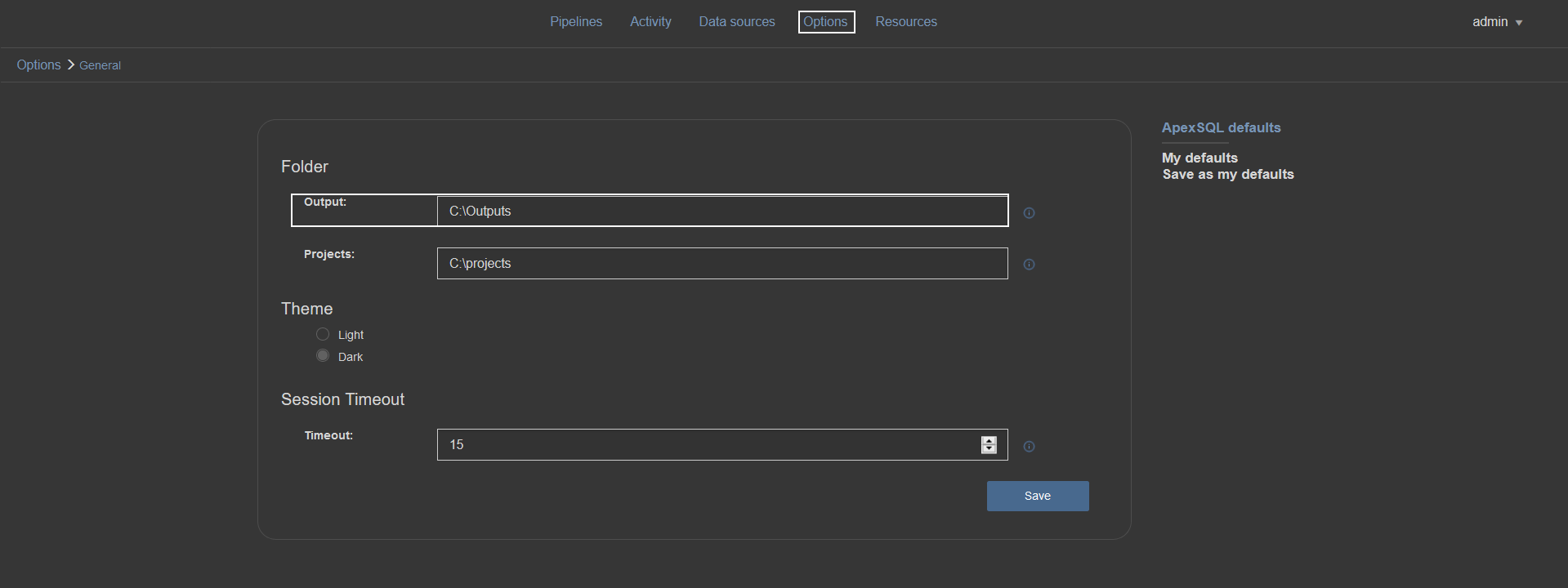
Output artifacts could not necessarily be stored in a NuGet package. For that purpose, the “Include output in package” option exists in every step that generates some output. Database deployment best practices indicate that every artifact should be stored in a package, therefore, this option is checked by default when starting a new step configuration.
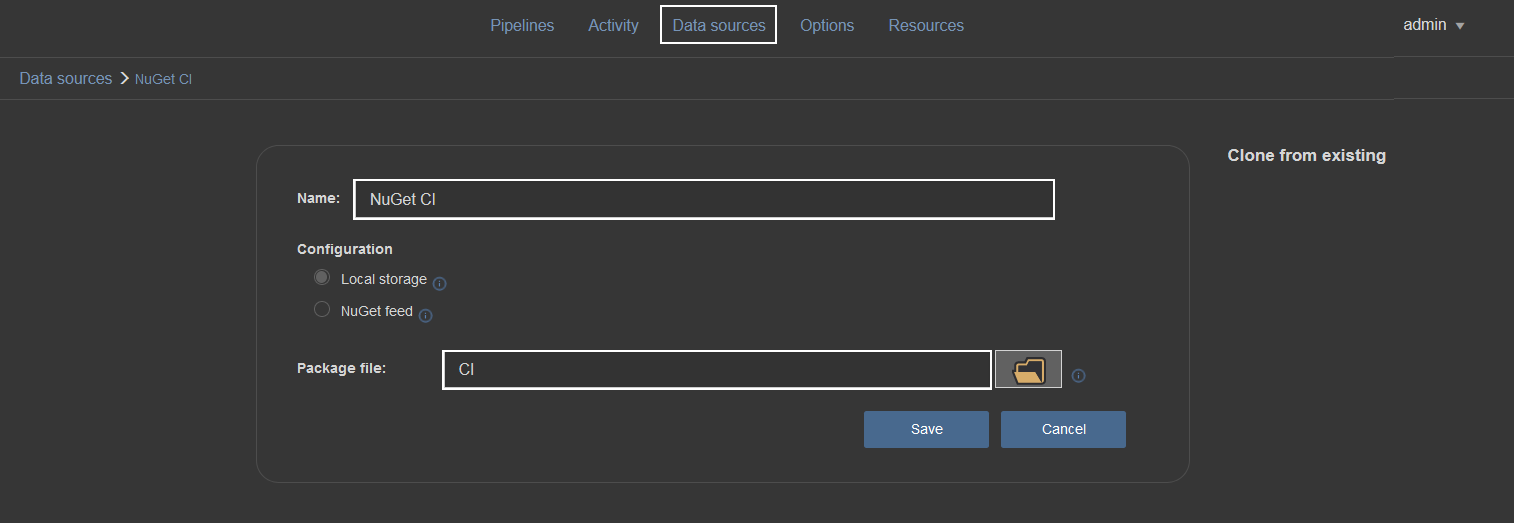
If “Include output in package” is checked, a NuGet package file definition will be required. This is done in the Data sources section with selecting the NuGet data source type:
A NuGet package file definition is created as the data source. The configuration requires only the package ID (with data source name identifier), without the package version number:
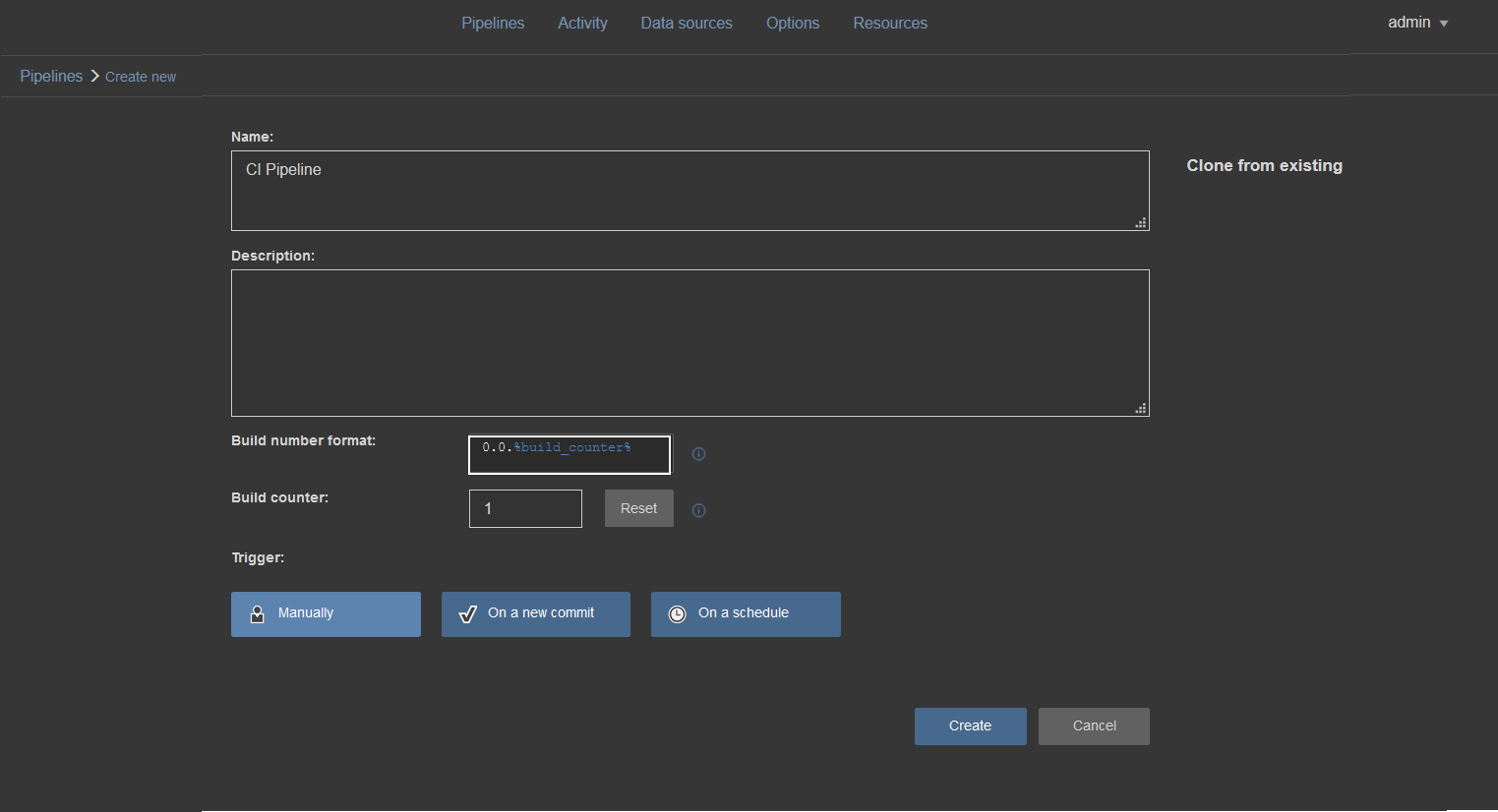
The version number will be automatically assigned based on the pipeline build counter settings:
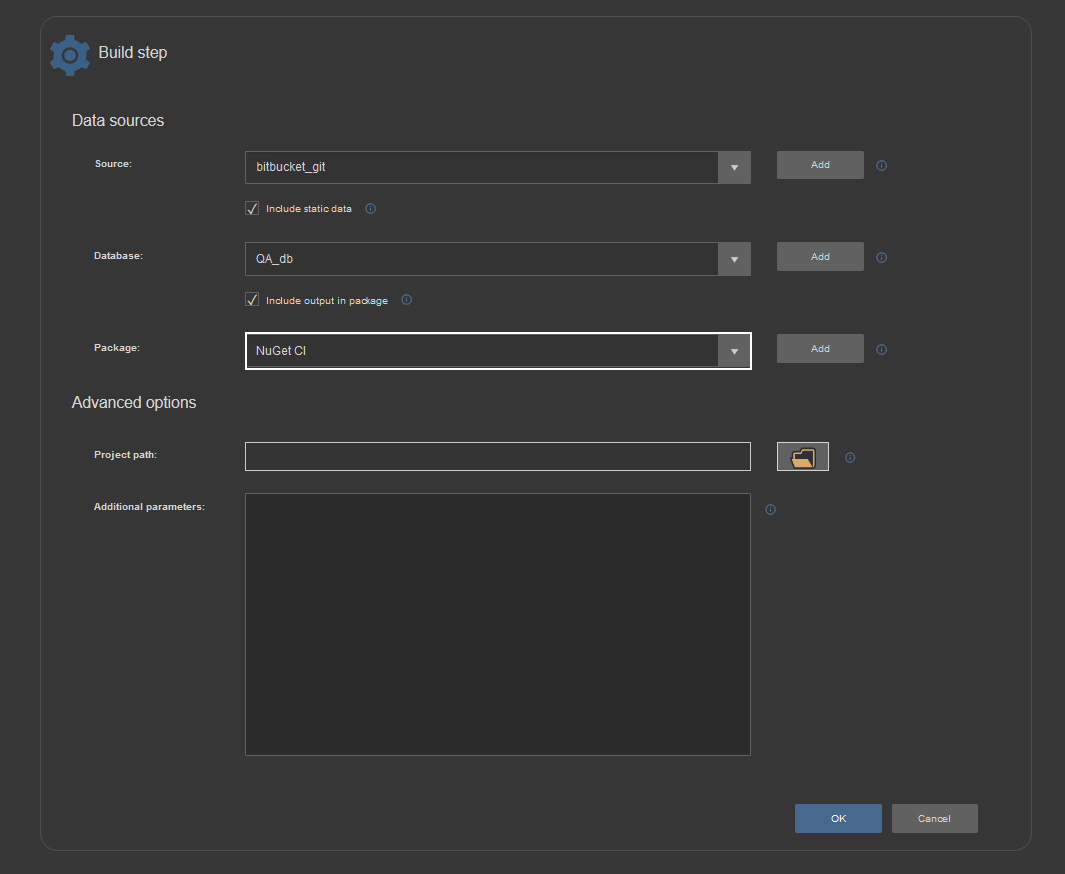
After the NuGet data source is created it can be consumed in a step if “Include output in package” is checked:
Use case
All steps provide relevant information as outputs that will help review a project workflow and troubleshoot issues. Creating and relaying a NuGet package with this information to a relevant person can be quite an organizational perk.
While working with a continuous integration pipeline the steps dedicated for this pipeline and their outputs would be:
Build step – builds a database from a provided source and outputs a Build summary (BuildSummary.txt) and a build SQL script (%data_source_name%_Build_script.sql). Build summary contains source and target connection messages generated by the ApexSQL Build tool and a set of SQL engine messages relative to executed SQL statements from the build script.
Populate step – generates synthetic test data to populate tables created with the Build step. It outputs information (Populate_summary.txt) about which tables are populated, with how many rows and if there are any issues encountered during the population test. It also creates a synthetic data population script in case it needs a review to check what kind of data was generated and possibly caused an issue, or it eventually provides the means for manual execution on another target.
Audit step – implements table auditing triggers on newly introduced tables if required. Output (Audit_summary.txt) gives information about which tables got triggers implemented and what type of triggers.
Review step – applies database project checkup against custom rulebase for coding best practices. It generates a detailed report (Enforce_report.html) on found issues, their impact level, where are they located and what type of issues. An additional summary is also created (Enforce_summary.txt) for a brief summary of what objects were processed.
Test step – Executes database unit tests against the built database. It generates a report (Test_summary.txt) on which unit tests were applied, their pass/fail status and a percentage of success.
Document step – creates database documentation, full or only with differences between current database project version and another database version. The output is database documentation (Documentation.chm) containing all information considering objects, properties, object scripts, etc. Another output file (Document_summary.txt) represents a brief overview of which objects were processed and included in the documentation.
Package step – the most important step in a continuous integration pipeline. As output, it creates a database script folder with scripted objects from the current database project. A package containing these scripts can be considered ready for synchronization and deployment of a new database version from the current project.
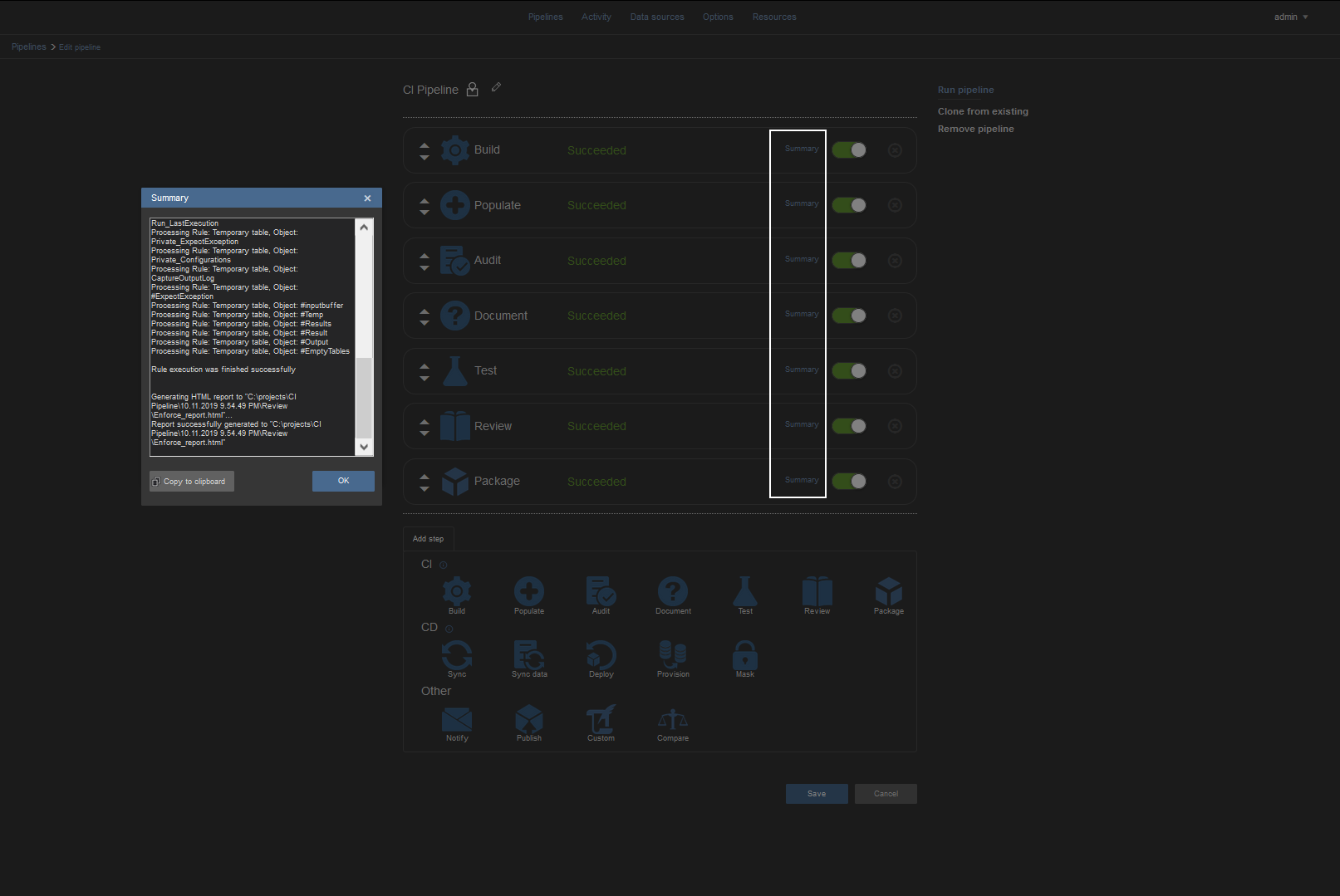
It’s worth noting that all summaries outputted by steps can be accessed from within the application, so for execution troubleshooting, direct access to output folder would not be necessary:
After a NuGet package with a database project is created there are several ways to store it and use it for deployment:
-
Importing package from local artifact repository (folder)
This is the usual way to prepare a package for manual deployment within a local network environment (with local area network infrastructure and shared folders). This means that further management of project deployment can be done on the same PC or on another with ApexSQL DevOps toolkit output location shared and mapped as a network drive on remote PC.
When a NuGet package is created and saved in a local repository a new NuGet type data source should be created but this time full path and file name for the desired package should be provided in order to consume existing NuGet:
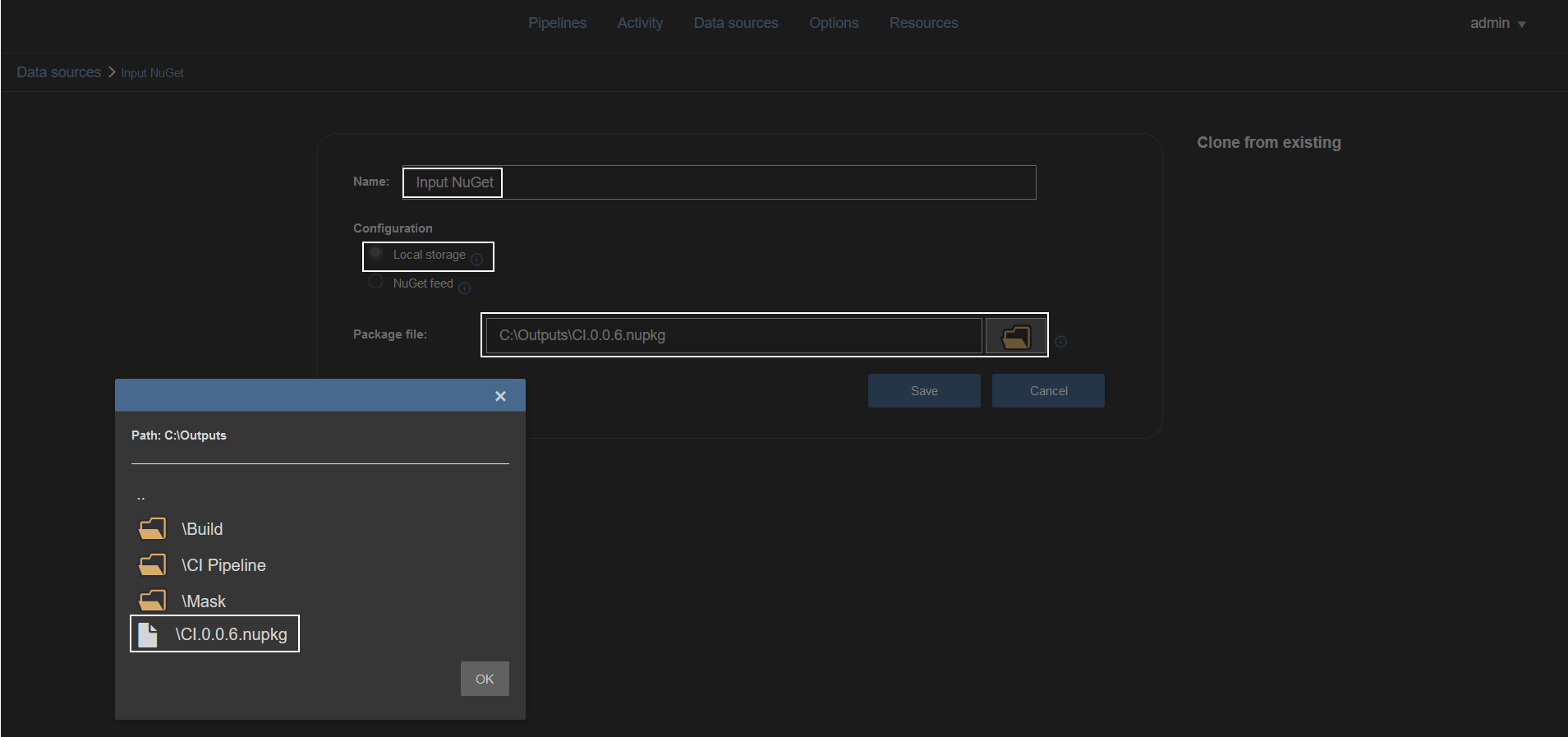
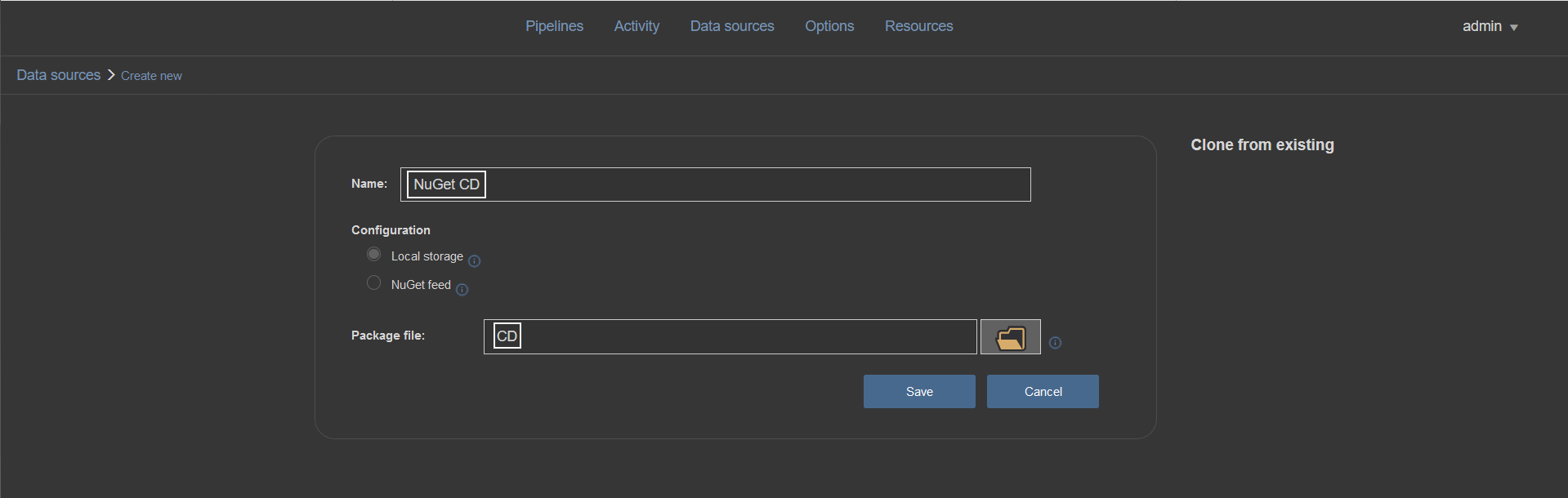
In addition to creating the input data source, another NuGet data source type should be created (e.g. named “CD”) to store outputs from continuous delivery pipeline steps which will process imported NuGet and create new outputs:
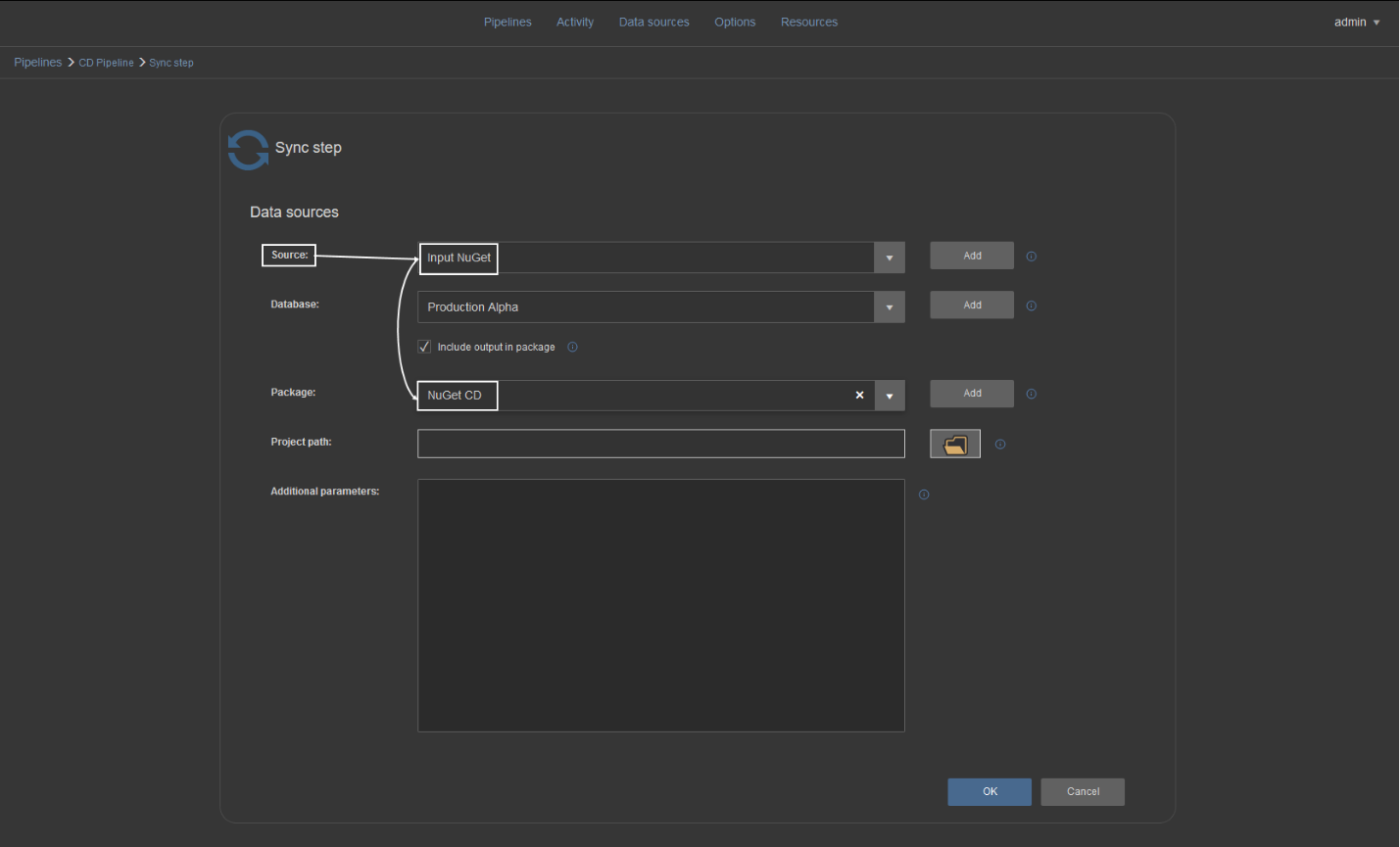
The final output of such pipeline will be a deployment package that contains synchronization SQL script which will update the database version. Steps and their outputs are:
Sync step – generates a schema synchronization script (SchemaSync_script.sql) based on the comparison between the database project and the target database. It creates also a schema difference report (SchemaSync_report.html) and comparison summary (SchemaSync_summary.log). Sync step also provides base elements for pre and post-deployment validation, an option that can be used in the Deploy step for deployment validation. This consists of the “SchemaSync_source_scripts” folder with copy of new, the project version of database and “SchemaSync_target_scripts”, a scripted version of the target database at the moment of synchronization script creation, and the respective summaries for those folder creation operations.
Technically, the Sync step will unpack imported NuGet package data source, process comparison between a database that was stored and extracted from package and a target database, generate previously described outputs and store them in a new package (the “CD” package):
Sync data step – generates a data synchronization script in case the database project is carrying some static data updates. Expected outputs are data synchronization script (DataSync_script.sql), data difference report (DataSync_report.html), data comparison summary (DataSync_summary.log) and a log with possible warnings (SyncWarnings.log)
-
Importing package from NuGet feed
To import a NuGet from an online feed first it has to be published to that feed. Publishing NuGet packages is done with the Publish step. This step should be used at the end of a pipeline and will need a NuGet type data source as input (the same used to store that pipeline outputs), the URL to NuGet feed (in this example the GitHub based NuGet gallery is used) and the API key that provides access to the designated gallery:
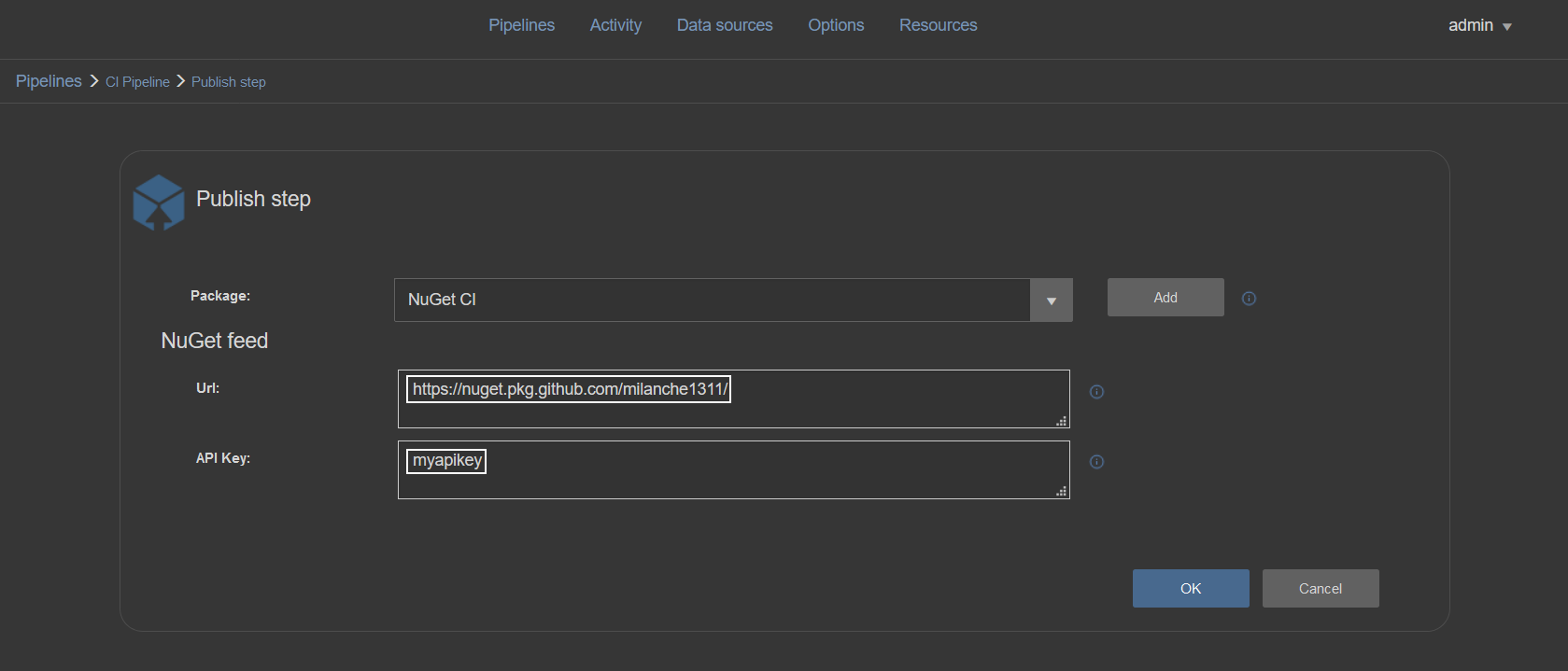
Using GitHub as NuGet package feed has its merits by allowing the package repository to be completely private compared to NuGet.org gallery but in comparison, it doesn’t provide API key which is required for the Publish step to upload the package. Obtaining the API key requires creating a NuGet source configuration with access credentials.
Creation of that configuration looks like this:
nuget sources Add -Name “SomeCustomSourceName” -Source “https://nuget.pkg.github.com/OWNER/index.json” -UserName USERNAME -Password TOKEN
Where:
- OWNER is a GitHub project owner (usually GitHub account name)
- USERNAME is the login user for GitHub account
- TOKEN is the replacement for password and its creation is explained here: Creating a personal access token for the command line
After that an API key can be assigned with the following command:
nuget setapikey CustomAPIKey -Source https://nuget.pkg.github.com/OWNER/index.json
With this configuration done and proper parameters are provided for the Publish step, after its execution, the package will be present in the gallery with its ID and version number (note that package ID, i.e. given NuGet file name, has to correspond to existing GitHub repository name):
Now a NuGet type data source can be created with provided URL and package name and version to be pulled from the gallery and used as input on continuous delivery steps. Note that if only package ID is provided and version omitted, the latest version will be pulled:

The step outputs will be handled the same way as in the situation previously described for local NuGet packages
-
Streaming a NuGet package from continuous integration to continuous delivery steps
It is possible to create a full pipeline that will use both sets of continuous integration and continuous delivery steps. In that case, the Package step will be used as usual but positioned in between the sets of steps to isolate and store database object scripts as explained previously:
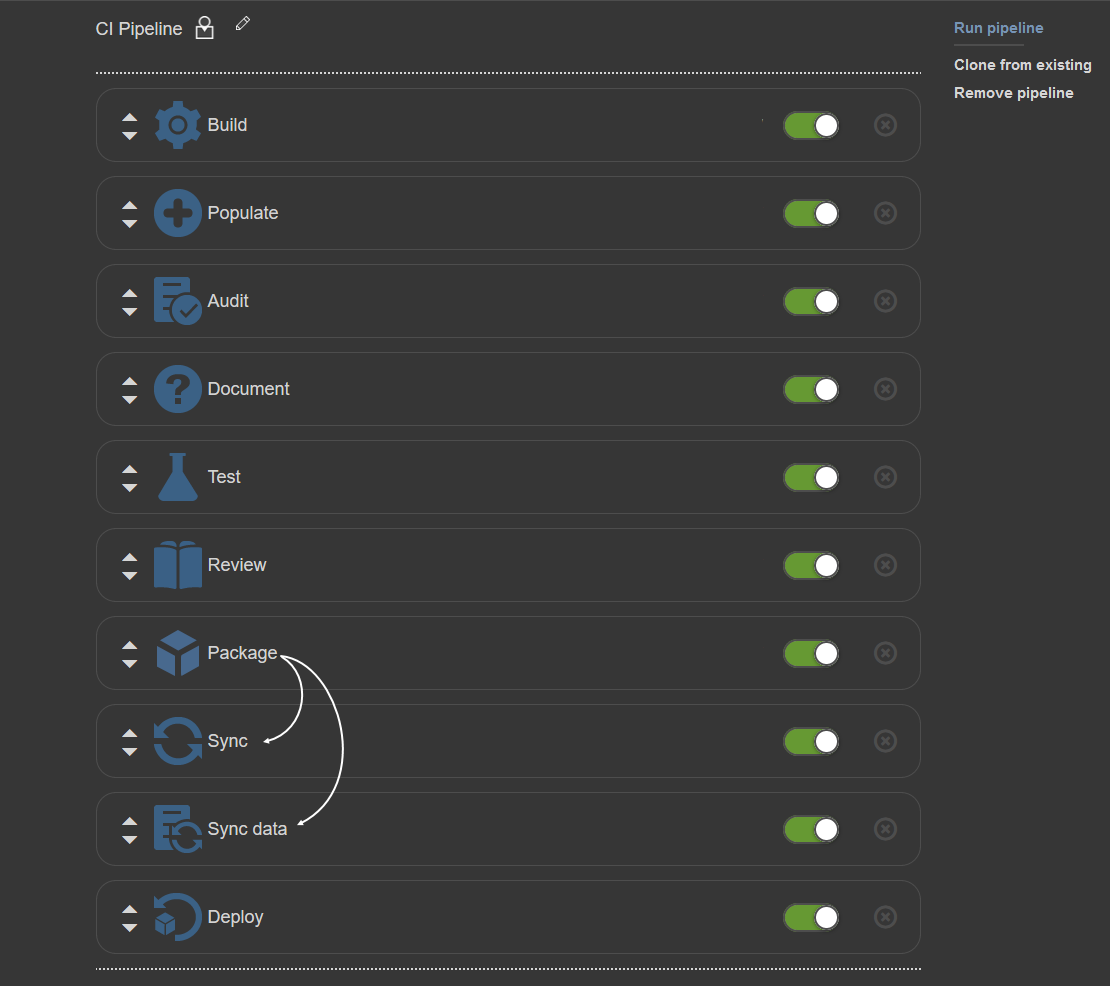
In that kind of sequence, Sync steps are added after the Package step and active NuGet will be used as input:
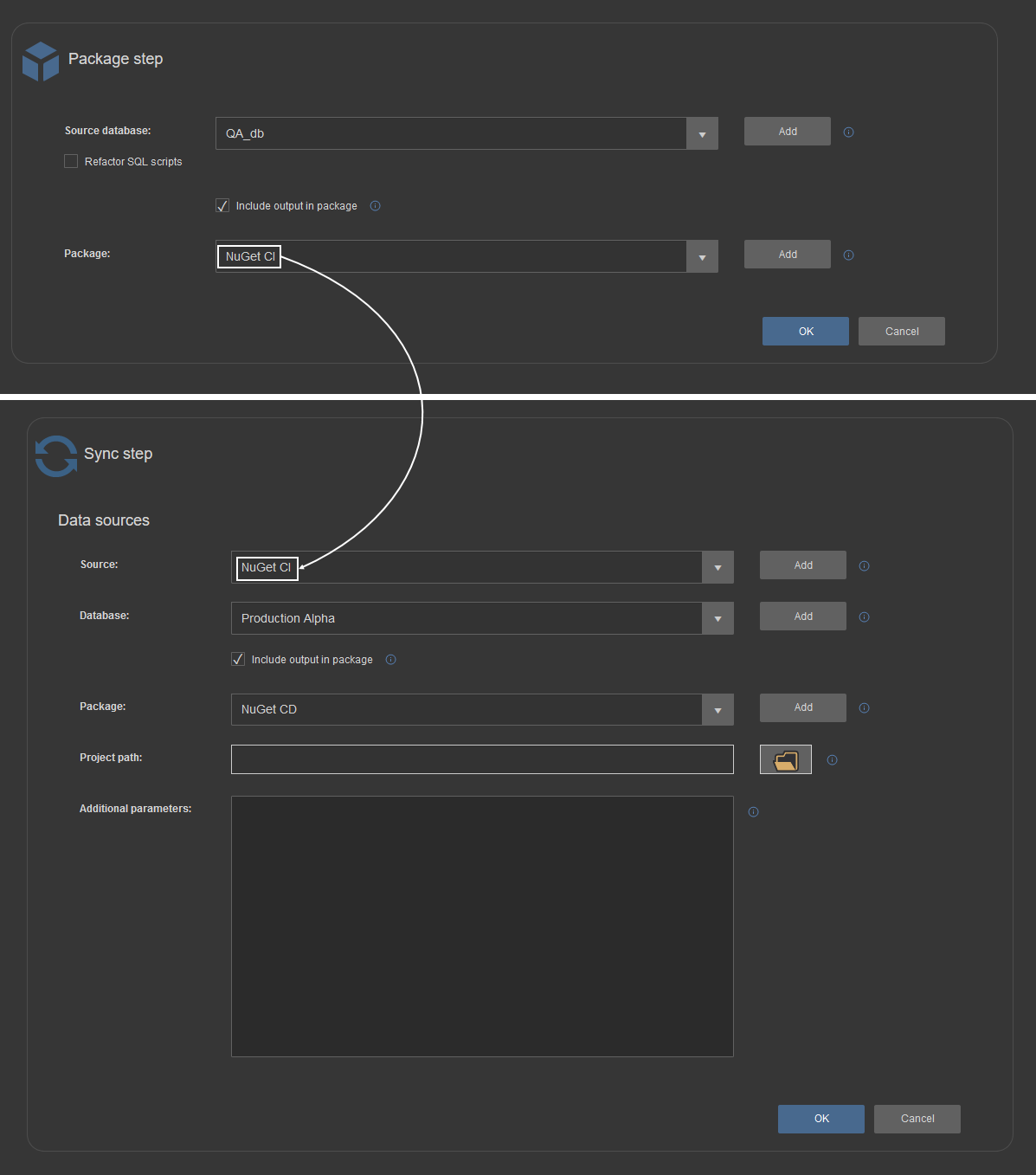
Again, it is recommended that Sync steps use the second NuGet type data source to store outputted synchronization scripts:
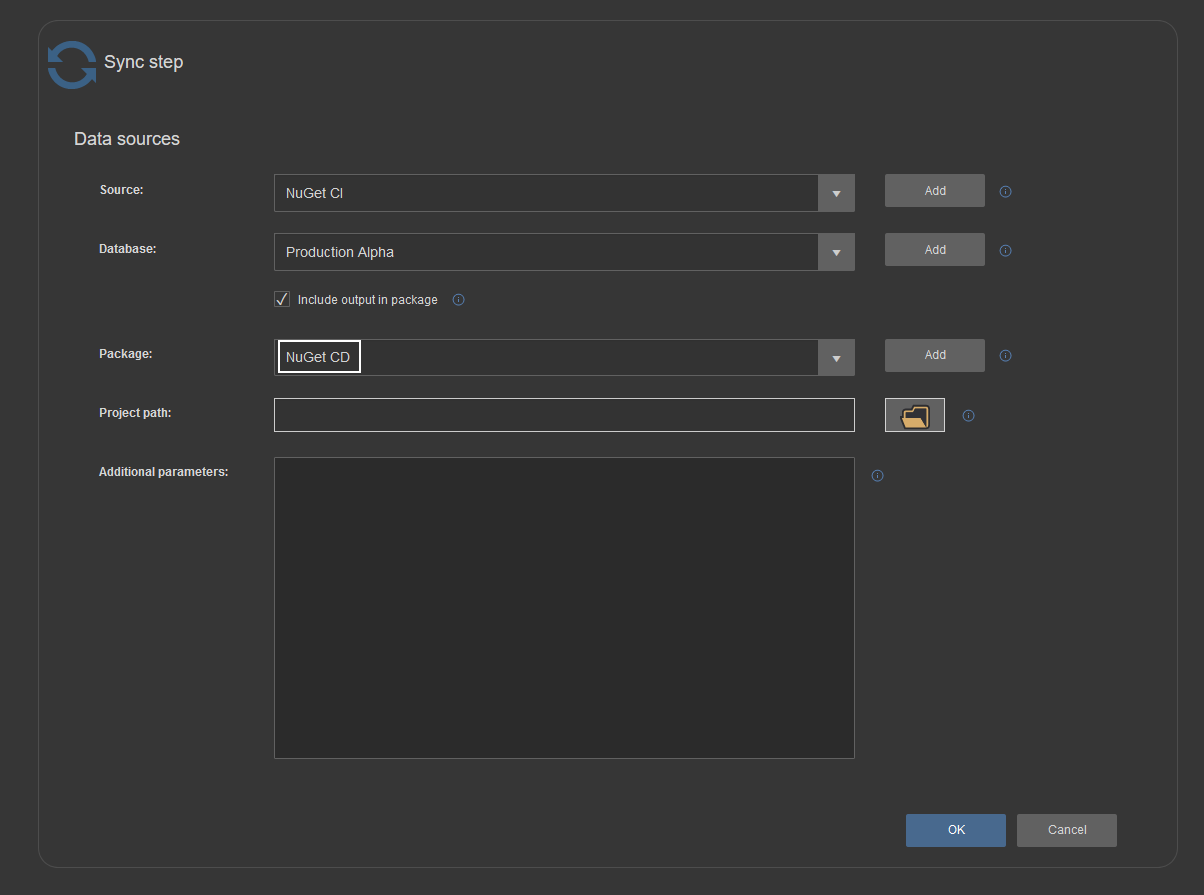
In this scenario, the Deploy step, which executes synchronization scripts, can be placed in another pipeline to execute it upon demand and in that case, previously explained NuGet sourcing method #1 and #2 can be used. Alternately the Deploy step can be used at the end of combined continuous integration and continuous delivery pipeline and streamed NuGet outputted from Sync steps can be used as input, the same way as for Package to Sync step transition. Naturally, this kind of full automation will prevent a manual review of generated outputs before deployment of changes but automated execution stops on found errors will somewhat compensate this.
ApexSQL DevOps compatibility
Considering that the ApexSQL DevOps toolkit has several variations, based on integration choice, the compatibility considering the usage of NuGet packages is present. This means that a NuGet generated as output in one ApexSQL DevOps toolkit solution can be used as input in another solution.
For example, a NuGet file created and published with the standalone Web dashboard solution during a continuous integration process can be used as input in a continuous delivery pipeline created with TeamCity plugin for deployment.
Conclusion
Based on the methodology explained in this article, it is easy to conclude that using NuGets in many ways increases the versatility of a database deployment process with ApexSQL DevOps toolkit and review management for each project or build version.