
Applies to
Summary
This article will explain SQL auditing activities and the data flow through the file system and network when the activities are on the run.
Details
Understanding the SQL auditing mechanisms that enable data flow throughout the environment and file system, provided by ApexSQL Audit, might help in better management and prevention of unintended issues and easy troubleshooting when an issue occurs. The article will explain what happens on the file system and how the central repository communicates with an instance from the moment the auditing is applied against it.
Auditing session initialization
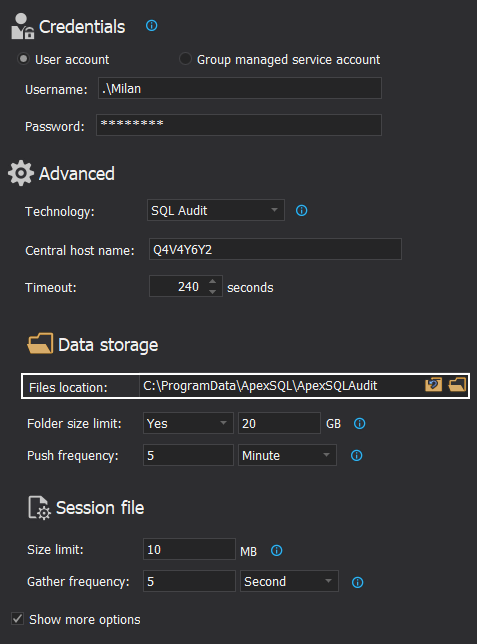
When SQL auditing is deployed and running, the audited SQL Server will write audited events on the file system in form of a session file. The location for the session files is custom-defined within the auditing agent configuration dialogue when adding a SQL Server for auditing using the ApexSQL Audit application. This option is labeled as the Files location within the Data storage section:
When the SQL Server auditing is configured and confirmed, a set of subfolders will be created on the designated temporary files location:
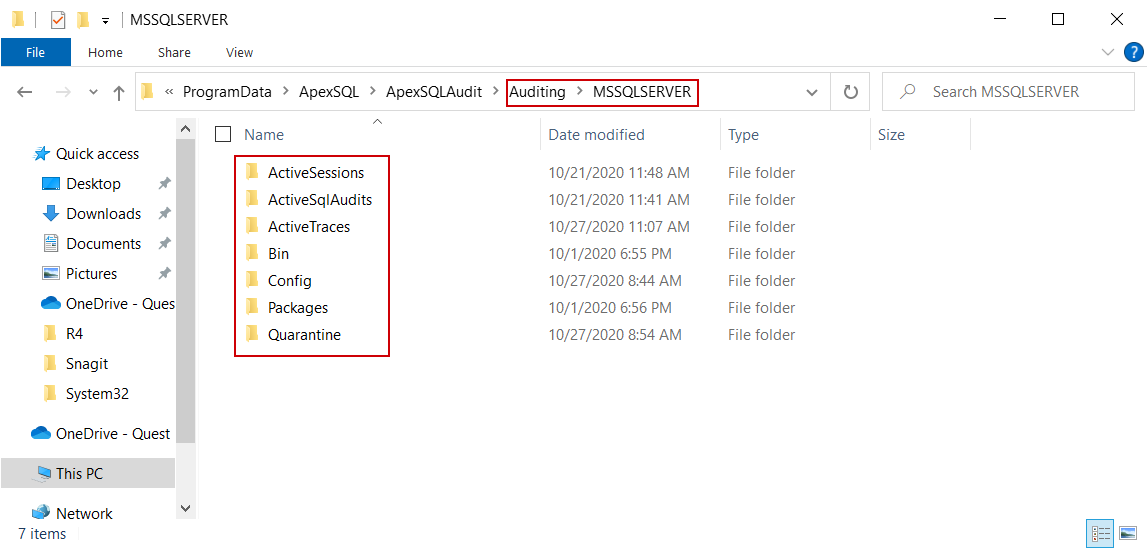
Based on the chosen SQL auditing data collection method the corresponding subfolder will be populated with session files:
- ActiveSessions – for the session files from the Extended Events data collection method
- ActiveSQLAudits – for the session files from the SQL Audit data collection method
- ActiveTraces – for the session files from the Trace data collection method
This structure will be created by the ApexSQL.Audit.Processor.Distributed process or, simply the distributed processor, which will be initiated upon applying the SQL auditing configuration from the GUI:
One of the initial actions of the distributed processor is to deploy the auditing session settings on the target SQL Server. This includes initial session parameters and filtering by events. It is initiated as a native SQL Server auditing session, only configured automatically instead of manually.
For example, the session based on SQL Audit technology can be seen from the SSMS’ Object Explorer as ApexSQLAudit object in the Audits folder and its filter configuration as the object in the Server Audit Specification (both are located under the Security folder). One of the parameters would be the temporary or session files location and can be recognized in the screenshot below:
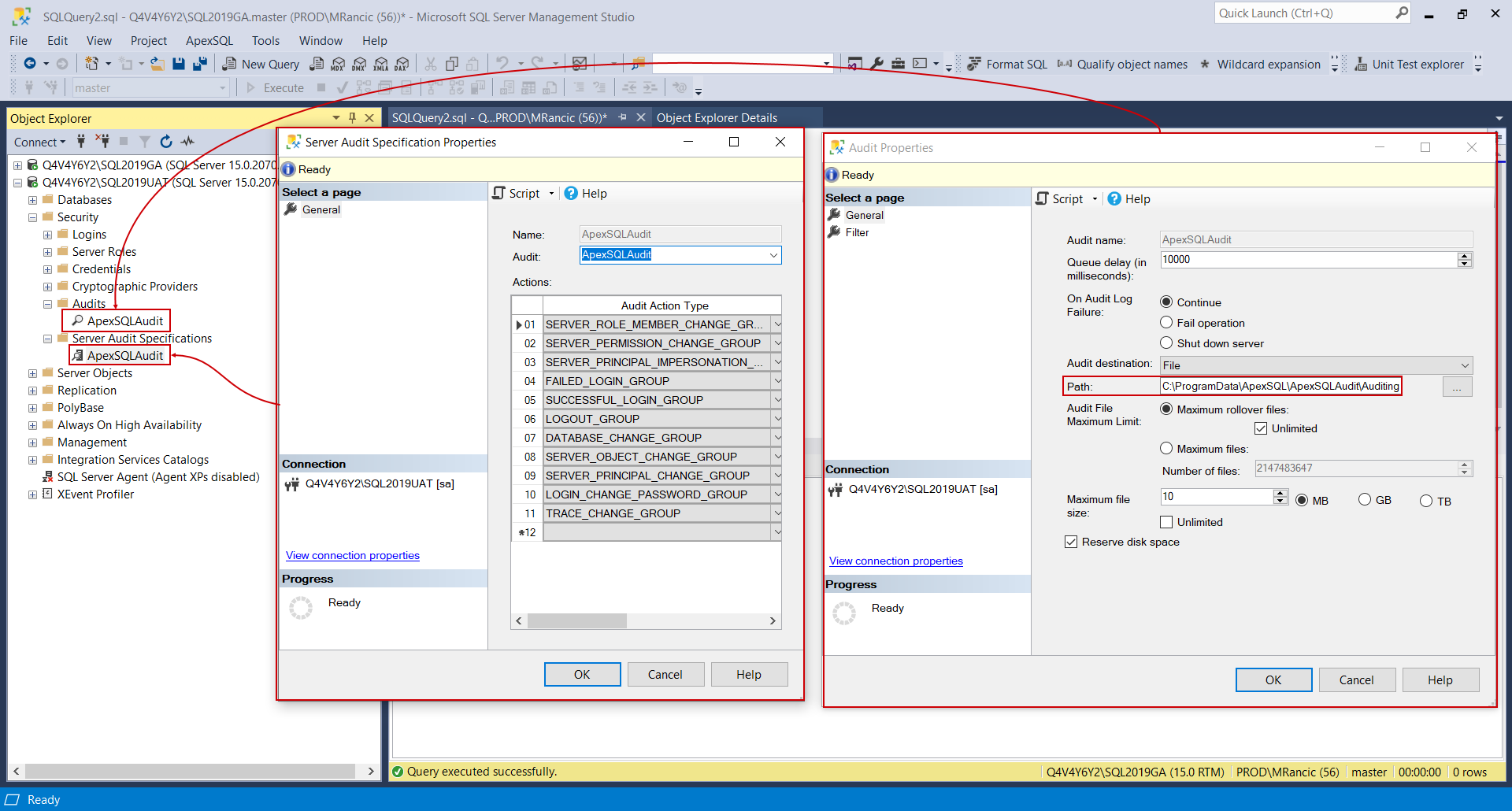
So, in case there are no objects with this name in these locations after auditing configuration is deployed from GUI there could be some issues with communication with the target SQL Server or with filtering setup.
Processing audited data files
If an audited event occurs, the SQL server will write it in a session file and save the file in the corresponding location, i.e. one of the aforementioned subfolders, based on what data collection method is used for that kind of event. Note that the level of encryption in those session files is based on SQL Server native mechanisms. The session file names will have a GUID type of format and, for example, a trace session files would look like this:
Now the distributed processor will begin with its activities again. It will read the data from the session files and will query the SQL Server in order to process them – to filter out unnecessary information, compact it to correspond to applied filtering, and pack them in package files that are encrypted by AES256 encryption. These package files will be saved in the Packages subfolder, located in the same temporary files location as the session subfolders. The schematic representation would look like this:
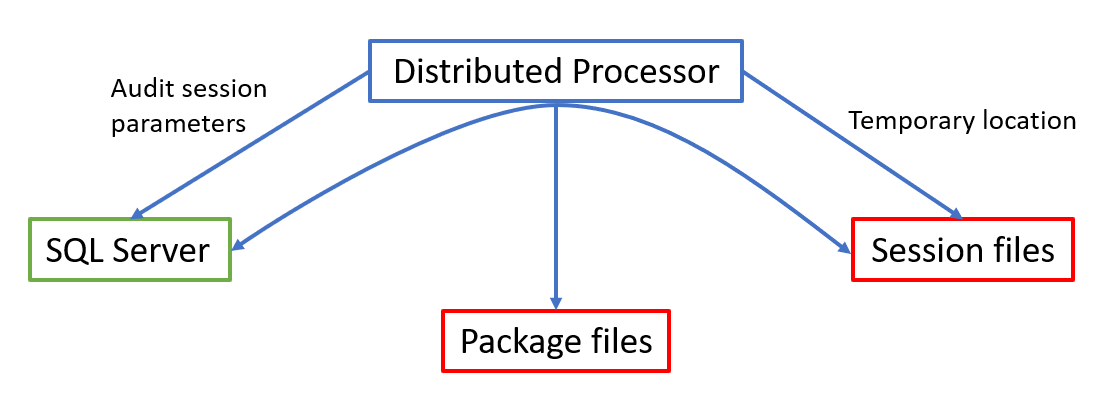
This data workflow can be easily used for troubleshooting SQL auditing issues. If there is no occurred event found in the auditing reports it is possible to check if the elements in this chain are out of order. For example, if there are session files that means that the auditing session is active but if there are no package files, that could mean that the distributed processer doesn’t have access to either temporary location or SQL Server.
- To troubleshoot such issues and check if all permission requirements are met, see the article: ApexSQL Audit – Permissions and requirements
The distributed processor is processing session files in bulks and discrete intervals. The interval between processing can be customized with the auditing configuration settings and it can be used to tune it for best performance, i.e. optimize the number of queries against the SQL Server in a given unit of time:
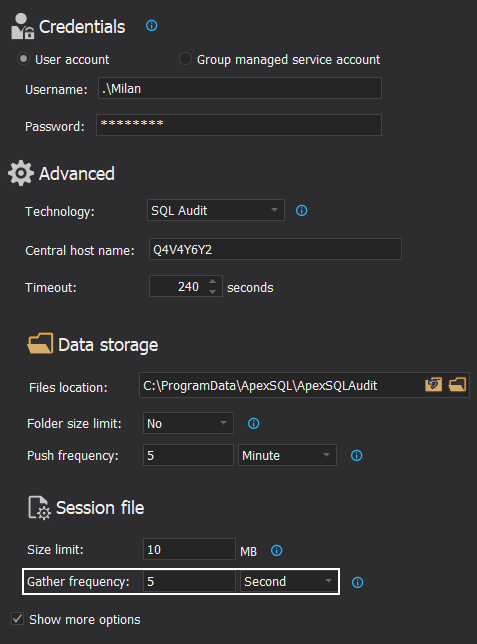
As part of session customization and optimization, it is also possible to define the size of session files before the rollover occurs (which might help clearing them out from storage space in desirable velocity), and to limit the size of the folder containing session files:
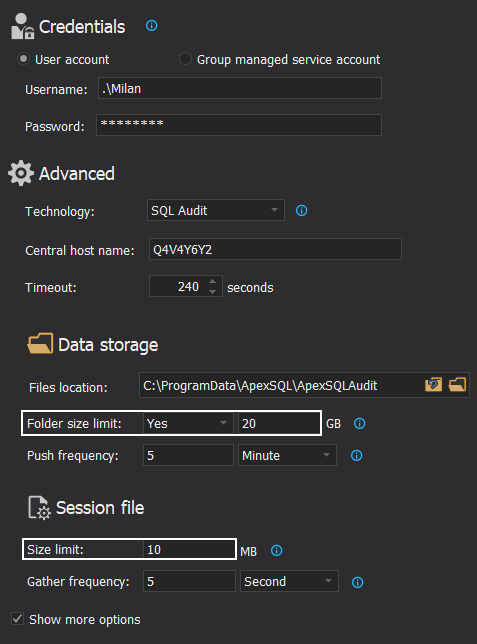
If the folder size reaches the defined limit, it will stop auditing and start it again when it gets cleared out. Stopping SQL audits is not a desirable effect, but this limiting can help in situations where free storage space is not in abundance and filling it up to the maximum might cause even greater issues, like getting other storage dependent services to a halt (this scenario is possible if there is an issue where the distributed processor cannot clear out session files in a timely manner due to high SQL Server traffic and a large influx of audited data).
Importing audited data to the repository
After a session file is processed, and a package is created the distributed processor will try to send it immediately to the central instance temporary files location. This location is defined on the ApexSQL Audit installation and is a part of the central instance repository configuration that deployment:
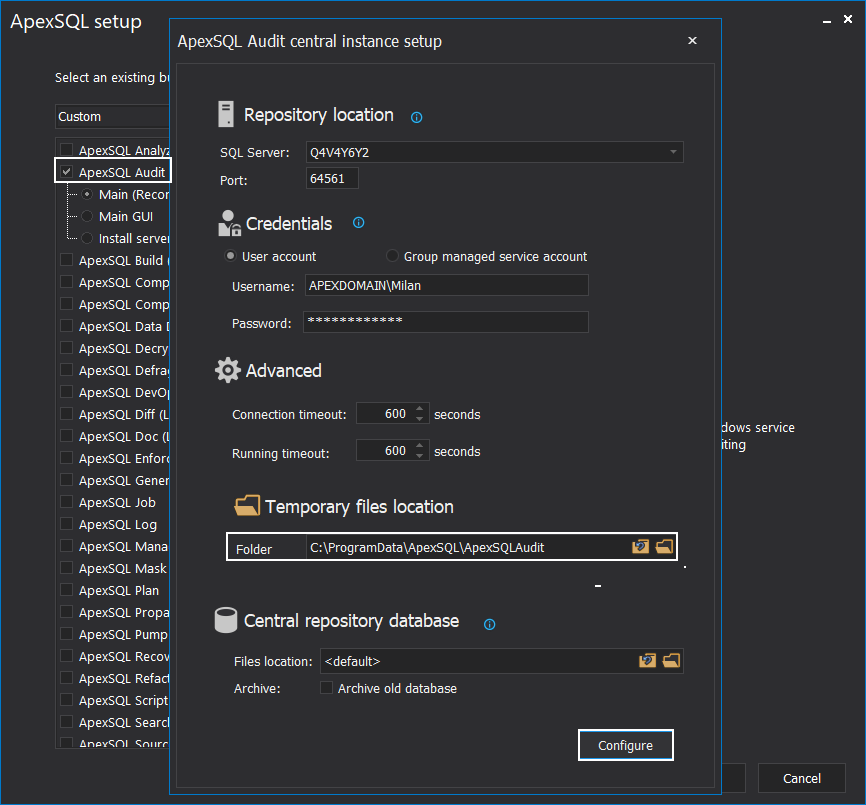
The temporary files location does not require to be shared and visible on the network as the ApexSQL. Audit.Processor.Central process, or simply the central processor will behave like an agent that will receive package files and place them in the designated location:
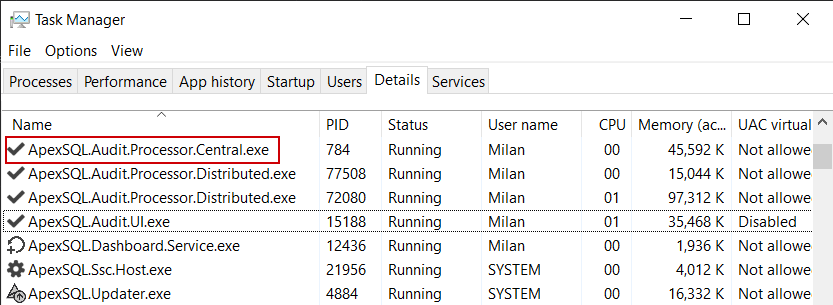
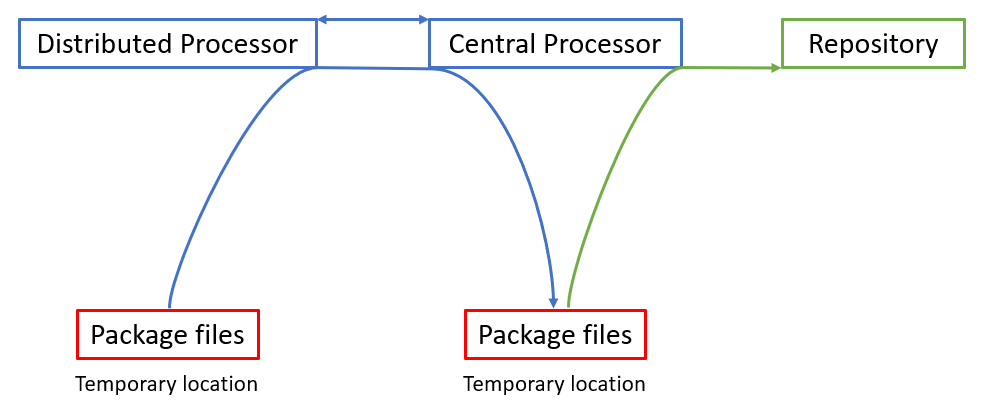
The transfer of packages can be described with this workflow:
- Distributed processor signals the central processor through established TCP connection (port 60408) and checks if it is active and available
-
If the central processor is active the distributed processor immediately sends package files through the same TCP connection (note that, besides already applied AES256 encryption for the files, the TCP/IP protocol will apply additional TLS security protocol)
- The central processor captures the data packages and saves them in the temporary files location:
- The central processor then queries the SQL Server instance hosting the repository, writes the data in the corresponding tables, and deletes the package
If writing to the repository database fails due to the SQL Server inaccessibility, the packages will remain there and will be imported when the SQL Server becomes available.
If writing to the repository database fails due to some other reason, like broken data format in the package file, it will be moved to the Quarantine folder and can be submitted for analysis.
Schematic representation of this workflow would look like this:
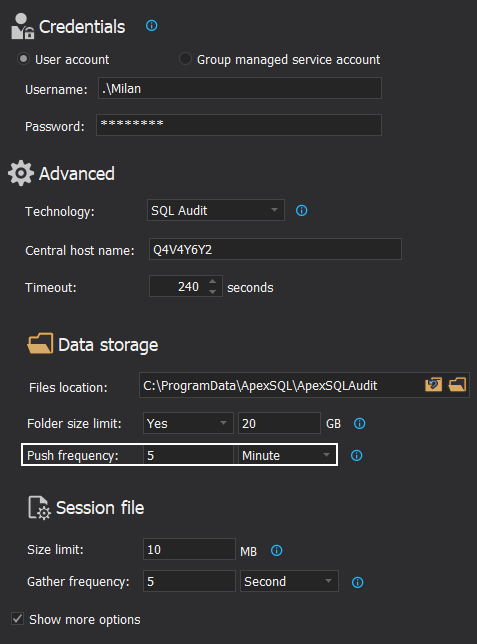
In case communication from the distributed processor to the central processor fails, due to a network issue or if the central processor is down, the distributed processor will try sending a re-attempt on the custom defined period. The interval is defined with the SQL auditing configuration deployment:
Understanding the workflow explained in this article might help in better organization of SQL audit environments and could indicate at what point should troubleshooting started if an issue occurs.