
Applies to
ApexSQL Refactor
Summary
This article describes the benefits of using ApexSQL Refactor options for Wildcard expansion and follow SQL Server query design best practices.
Description
There are several reasons to list table columns in a SELECT statement in production code over using the SELECT * (aka “wildcard”) syntax:
Maintenance: A common misuse of SELECT * is selecting all columns from a table and inserting them into a table with the same structure:
INSERT INTO Emails SELECT * FROM EmailsCustomers WHERE EmailID = 23;
In case the business requirements change and more columns are added to or deleted from a table, using SELECT * will result with a syntax error e.g.:
ALTER TABLE EmailsCustomers ADD MiddleName varchar (10)
Running the previous SELECT * statement will result in an error:
Msg 213, Level 16, State 1, Line 1
Column name or number of supplied values does not match table definition.
A similar error is encountered if there is a view that extracts all columns from a referenced table e.g.:
CREATE VIEW vwEmails AS SELECT * FROM Emails WHERE EmailID = 23; ALTER TABLE Emails DROP COLUMN MiddleName
Running the following SELECT statement results with an error:
SELECT * FROM vwEmails;
Msg 4502, Level 16, State 1, Line 1
View or function ‘vwEmails’ has more column names specified than columns defined.
Performance: Selecting too many columns in a SELECT statement can increase data transfer across the network, produce additional reads, force clustered index scans for the query execution plan etc.
The following queries give different execution plans for the SELECT * syntax and for a query with listed only needed columns in the SELECT statement. Query with SELECT * is forcing the Clustered Index Scan for the query execution plan:

Beside the fact that the Index seek is in this case much more effective method, the first query also produces additional reads:
Query using SELECT *:
(678 row(s) affected)
Table ‘TransactionHistoryArchive’. Scan count 1, logical reads 628, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Query with only needed columns listed:
(678 row(s) affected)
Table ‘TransactionHistoryArchive’. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
|
Quick tip: An object (a view or a function) created with the SCHEMABINDING option doesn’t using SELECT * |
The following statements with the SCHEMABOUND option will fail to execute:
CREATE VIEW vwJobs WITH SCHEMABINDING AS SELECT * FROM HumanResources.JobCandidates;
Msg 1054, Level 15, State 6, Procedure vwJobs, Line 4
Syntax ‘*’ is not allowed in schema-bound objects.
The statement with the properly listed columns will execute successfully:
CREATE VIEW vwJobs WITH SCHEMABINDING AS SELECT JobCandidates.JobCandidateID, JobCandidates.BusinessEntityID, JobCandidates.Resume, JobCandidates.ModifiedDate FROM HumanResources.JobCandidates;
There are two ways to expand wildcards in ApexSQL Refactor:
Open a SQL script in SQL Server Management Studio and select part of the script that needs to be formatted, otherwise the whole script in the query window will be formatted:
- From the ApexSQL Refactor menu, select the Wildcard expansion command:
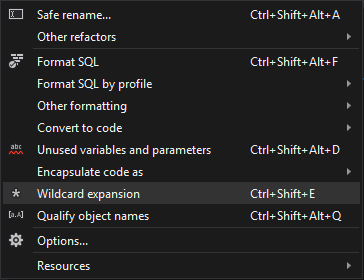
- Use the Ctrl + Shift + E shortcut
ApexSQL Refactor expands the following SELECT statements and lists all of the columns in referenced tables: SELECT *, SELECT alias.*, and SELECT table.*.
SELECT c.* FROM Customer c;
Using the Wildcard expansion feature statement is formatted as:
SELECT c.CustomerID, c.FirstName, c.LastName, c.Email, c.PhoneNumber FROM Customer c;SELECT * FROM Customer;
Using the Wildcard expansion feature statement is formatted as:
SELECT Customer.CustomerID, Customer.FirstName, Customer.LastName, Customer.Email, Customer.PhoneNumber FROM Customer; SELECT Customer.* FROM Customer;
Using the Wildcard expansion feature statement is formatted as:
SELECT Customer.CustomerID, Customer.FirstName, Customer.LastName, Customer.Email, Customer.PhoneNumber FROM Customer;