
Applies to
ApexSQL Enforce
Summary
Sometimes failing is good and ApexSQL Enforce provides several possibilities to make sure this happens when deserved, at least.
Description
This article will explain the concept of failure in ApexSQL Enforce and why is it important to fail correctly.
The concept of failure in ApexSQL Enforce
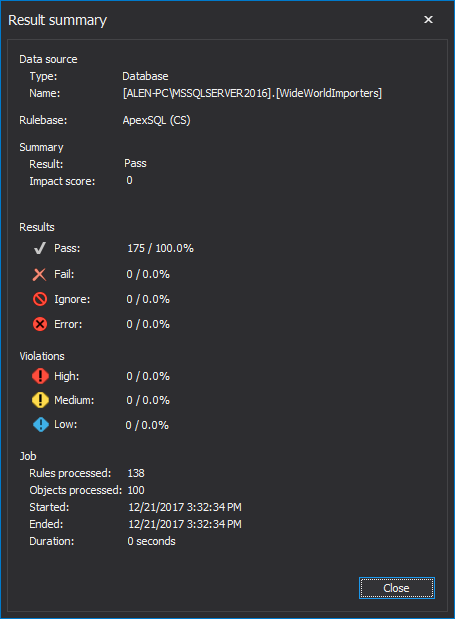
The concept of failure in ApexSQL Enforce is when the results are so bad, that they fall below some pre-set minimum threshold of acceptance.
This may include one or more variables that exceed a certain tolerance:
- An impact score
- A number of absolute rule failures of a certain severity
- A certain number of rules completing with errors
|
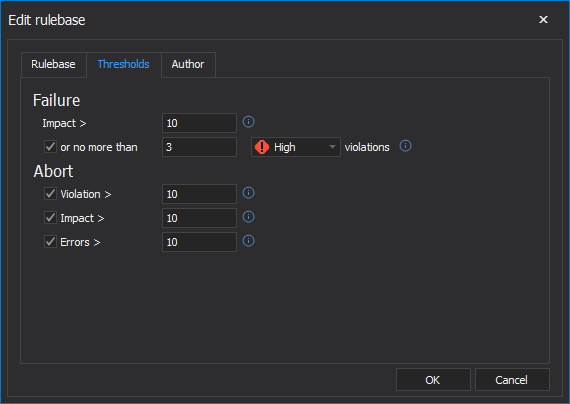
Quick tip: Failure threshold can be set in the Threshholds tab in the Edit rulebase window. Different failure thresholds can be set differently for each rulebase. |
Failing
The impact score is a weighting applied to severities. For example: if you have designated, for a particular rulebase that a violation with High severity has an impact score of 10. If your rulebase is processed against a particular target and 3 violations of high severity, were raised, that will result in an impact score of 30. If your threshold for job level failure is 100, you are OK. But if you get 15 such violations of high severity, with an impact score of 150 you aren’t. The rule base will complete with a result of failure
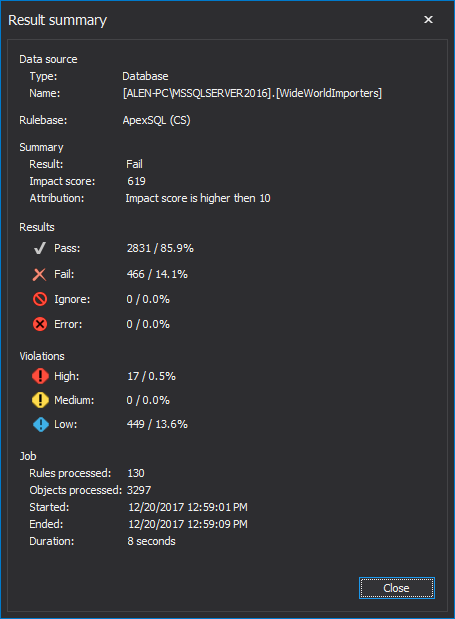
Regardless of the impact score, the perfectionists among us may want to fail a particular job simply because a certain number of violations were raised of a particular severity. So, if a tolerance is set to fail if even 1 violation with High severity is raised, then any such violation will fail the job.
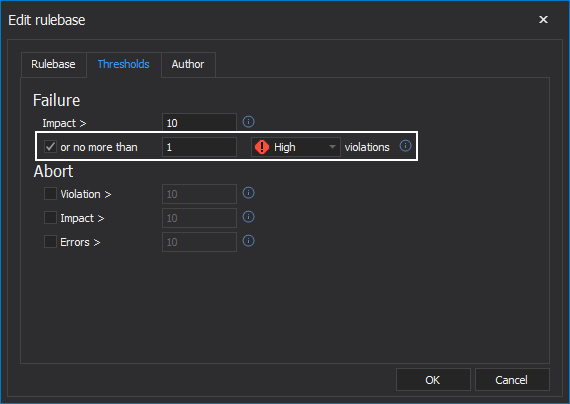
Aborting
In some circumstances, you might want to avoid continuing to run a long job if it has already failed. This can be helpful if jobs can take a long time to complete and you want to get bad news back sooner. If this is the case, you can tell ApexSQL Enforce to abort in certain circumstances including:
- A high number of absolute rule failures
- A particularly high impact score
- A certain number of rules that experienced errors when processing
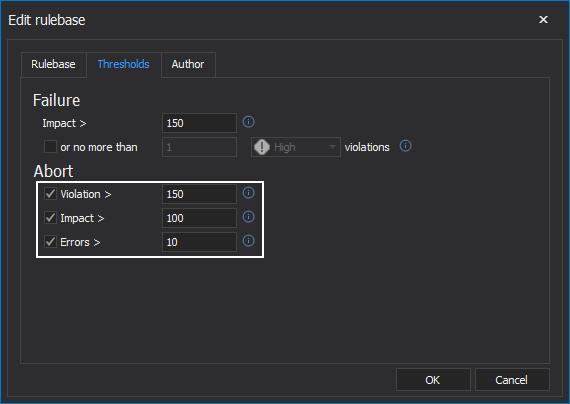
A job can be set to abort immediately on failure. In this way, processing is halted, and a failure return code is providing, to any calling app or script. This can be helpful to truncate a pipeline that is already DOA (dead on arrival) and get that information back to stakeholders expeditiously.
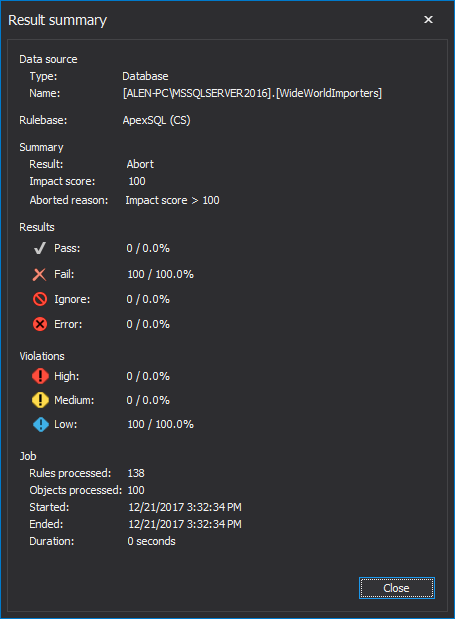
In addition, if a job is producing a lot of violations, even if it wasn’t set to abort on failure, continuing it might not be prudent. In this case a governor can be set to abort the job past a certain number of violations, regardless of severity.
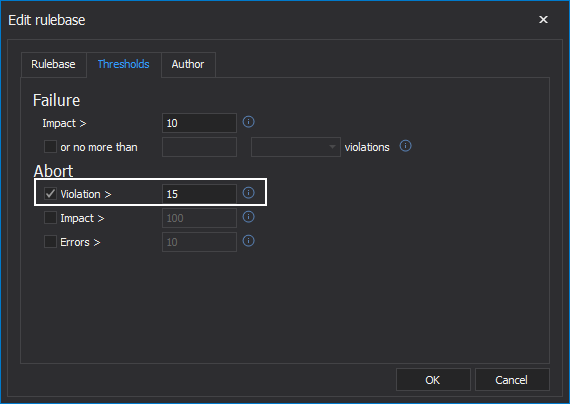
Similarly, if the job has failed, but the other team keeps running up the (impact) score, it might be time to call the game. Setting a maximum tolerance for continuing to play, via the impact score, can be helpful.
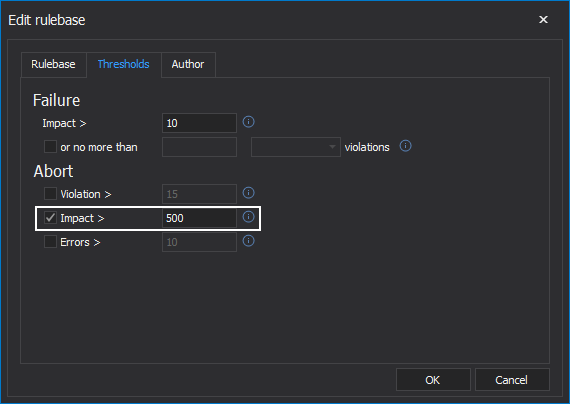
Finally, some users may want to fail a rulebase not because of violations that were raised but because of a high number of rules processed with errors. If this tolerance is set to zero, any error will result in the rulebase failing. This is helpful because, it isn’t possible to know what the result could have been. It might be a very critical rule. So, failing the job, fixing the problem, and re-running it might be the prudent result.