
Applies to
ApexSQL Data Diff, ApexSQL Diff, ApexSQL Diff for MySQL, ApexSQL Doc, ApexSQL Log, ApexSQL Script and ApexSQL Search
Summary
This article explains how to use .NET framework regular expressions in ApexSQL tools.
Description
A regular expression is a string that is used to describe or match a set of strings, according to certain syntax rules. For example, the set containing the three strings Handel, Händel, and Haendel can be described by the pattern “H(ä|ae?)ndel”.
Using regular expressions for filtering the Results grid in ApexSQL Log
ApexSQL Log has a custom search feature that supports regular expressions. In the ApexSQL Log toolbar, under the Home tab, click the Find option:

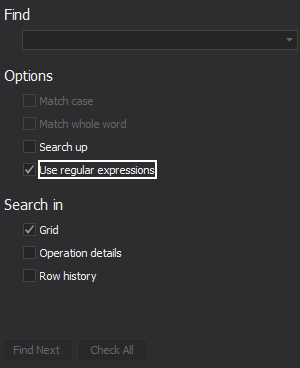
In the Find window, select the Use regular expressions option and enter the regular expressions pattern:
Using regular expressions for database text search
ApexSQL Search supports regular expressions to match the results in the Filter row option:

Using regular expressions in the Command Line Interface switches
ApexSQL Data Diff, ApexSQL Diff, ApexSQL Diff for MySQL, ApexSQL Doc and ApexSQL Script support a set of Command Line Interface switches for including into and excluding objects from the process. These switches accept regular expression patterns as parameters and act the way similar to the Object filter feature.
/inc – Specifies the objects to be compared using regular expressions
|
Quick tip: If the /inc switch is not specified, all objects are assumed |
/exc – Exclude specific objects in processing, objects can be specified by first specifying a bitwise set and after “:” a regular expression. Multiple excludes can be specified with spaces in between. The /exclude switch is processed after the /include switch.
Commonly used regular expressions
Here is the list of the most commonly used regular expressions:
|
^ |
Matches the start of the line (or any line, when applied in multiline mode) |
^B – This pattern matches any line that starts with “B” character |
|
$ |
Matches the end of the line (or any line, when applied in multiline mode) |
X$ – This pattern matches any line that ends with “X” character |
|
. |
Matches any single character except newline character “\n” |
i.ation – This pattern specifies any word starting with “i” followed by any single character and finished by “ation” substring (for example “isation”, “ization”) |
|
* |
A single character expression followed by “*” matches zero or more copies of the expression |
ra*t – This pattern specifies any word started with “r” and ended by “t” where “a” character can appear 0 or more times starting from the 2-nd position (for example “rt”, “rat”,” raat”, etc.) |
|
+ |
The previous character can be repeated 1 or more times |
ra+t – This pattern specifies any word started with “r” and ended by “t” where “a” character can appear 1 or more times starting from the 2-nd position (“rat”, “raat”, “raaat”, etc.) |
|
? |
The previous character can be repeated 0 or 1 time |
ra?t – This pattern specifies only one of the following: “rt” or “rat” |
|
\s |
Any space character |
\sa – This pattern specifies the “a” character preceded by [space] character |
|
\S |
Any non-space character |
\SF – This pattern specifies the “F” character preceded by any non-space character (for example”aF”, “rF”, “cF” but not [space]F ) |
|
\b |
The character representing the word boundary |
ion\b – This pattern specifies any word that is ended by “ion” |
|
\B |
The character at any position except of the word boundary |
\BX\B – This pattern specifies any word with “X” character in the middle of the word |
|
Quick tip: For a full list of regular expressions visit the following link |
Examples of regular expressions patterns
To find all objects that start with Product e.g.: Products, ProductPrice, ProductPhoto, ProductCategory, etc., use the ^Product pattern.
To find all objects that end with _Archive e.g.: Product_Archive, ProductPrice_Archive, ProductOrder_Archive, etc., use the _Archive$ pattern.
Using only one placeholder in a pattern is a quite rare situation and most of the times a pattern contains two, three, or more placeholders:
(^Link|Link$) – selects all objects that start or end with the word link e.g.: LinkProductPhoto, OfficeCityLink, etc.
\s – selects all objects that have spaces in its name, e.g.: [Long String], [Table With Data], [Table Name].
\s\s+ – selects all objects that have two or more spaces consecutively in its name, e.g.: [Table With Too Many Spaces], etc.
^sp_(a|z)– selects all objects that start with the letter a or z in its name after the _sp prefix
\d$ – selects all objects that end with a number, e.g.: Table1, sp_columns_90, etc.
\S+_os_\S+ (or \B_os_\B) – selects all objects that contain _os_ in the middle of the name, for example: dm_os_workers, dm_os_tasks system views.
Photos?\b – selects all photos related objects like ProductPhoto, EmployeePhotos, but not the ProductPhotoFileNameobject
\b.._\B – selects all objects with a prefix in form of XX_ for example system objects db_datareader, sp_pkeys, fn_dblog, etc.
^sp_\S*Read$ – selects all objectswith the sp_ and the suffix Read for example, sp_DocumentRead, sp_Price_Read, etc.
^fu?n?c?_\B – selects objects with prefixes with the following letter combinations: f_, fn_, func_, fnc_, etc. For example: fn_dblog, f_dataReader, fnc_updateProduct, but not ufnDataRead.
sys(tem)?– selects all objects that contain sys or system in its name
\bS(a|h) – selects objects that have “Sa” or “Sh” as the start of any word
\^sp_(update|delete)\B – selects objects that have the sp_ prefix and update/delete as a name prefix. For example: sp_deleteLog, sp_updateDocumentPrice, etc.