
Applies to
ApexSQL Generate
Summary
This article explains how to apply table mapping in ApexSQL Generate, its types, usage and benefits.
Description
Table mapping represents copying data from an external source (a CSV file or an SQL table) into the selected table at the column level. It allows transferring data from an existing source to multiple columns of the selected target table in one go, by using mapping dialog.
Table mapping can be used in cases when large or small amount of data needs to be imported from a source tables or files into the target table.
The mapping process is happening between two objects: source table or a file and a target table.
The source is the object that contains the data to be transferred. Source table or source file contains source columns.
A target table is an SQL table in the opened ApexSQL Generate project where the data from the source is transferred to. Target table contains target columns.
In order to achieve mapping, at least one of following conditions must be satisfied:
- Source and target columns have exact data types (they are compatible) or
- Data from source column can be parsed or converted into the target column’s data type.
In ApexSQL Generate, there are two types of table mapping:
- Map test data from a SQL table or view
- Map test data from a CSV file
Both types of mapping consist of three steps:
- Loading the source
- Matching (mapping) the source columns to the target columns
- Applying changes
The only difference between these two table mapping types is in the first – loading the source.
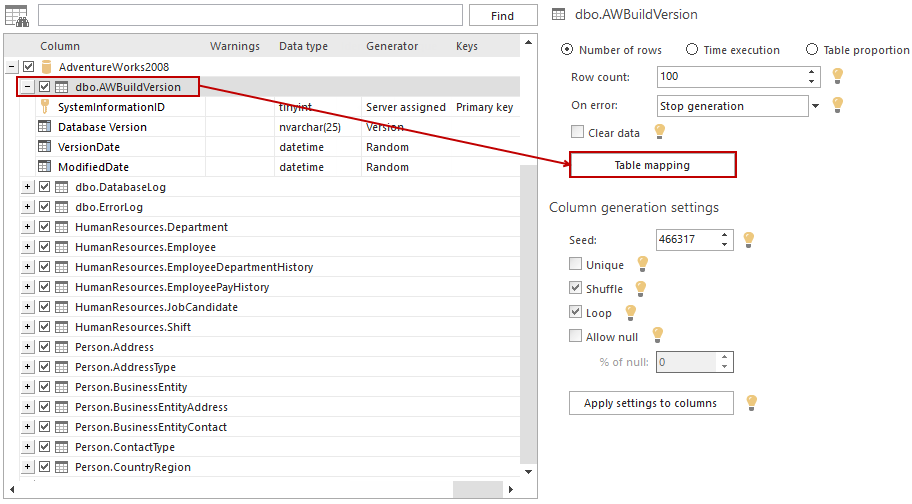
After selecting Table mapping at table settings pane, a table mapping dialog is presented.
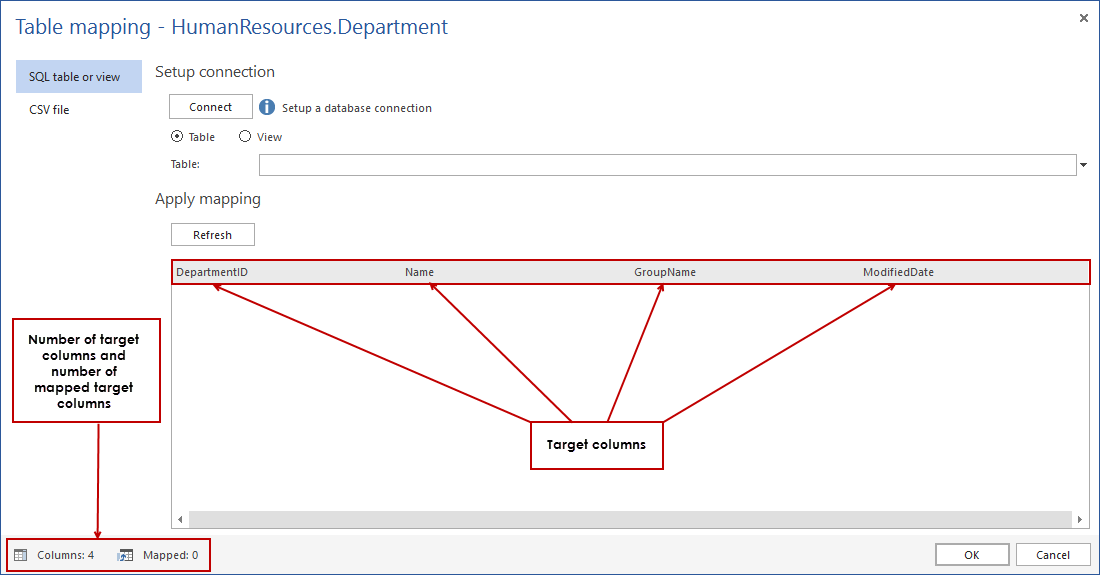
Map test data from a SQL table
The first step in the table mapping process is to setup connection to the source database using the Connect button.
After establishing connection, tables or views of the source database can be chosen by selecting the Table or View radio buttons, after which the combo box will be populated with the selected objects.
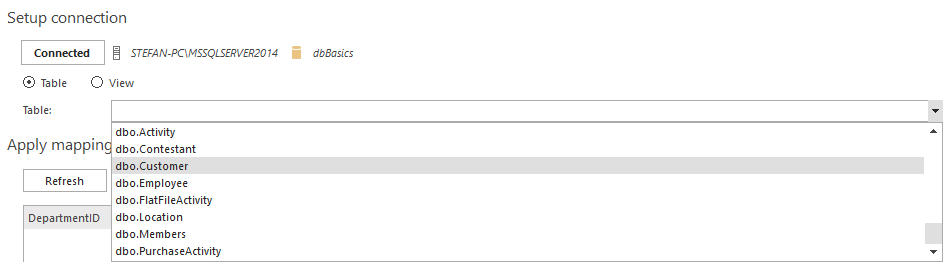
After the table or view selection is committed, test data will be imported and presented in preview grid.
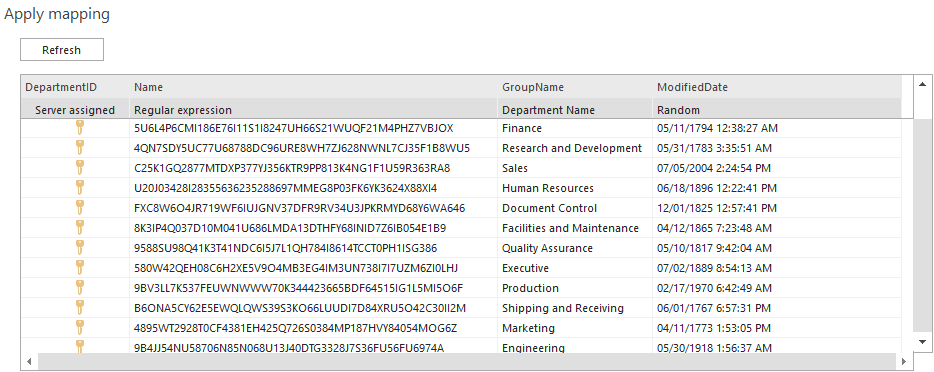
By default, table mapping will determine matching columns by comparing their data types and column names. In this example, the target and the source tables contain columns LastName and FirstName sharing same data types (nvarchar) and they are automatically being mapped.
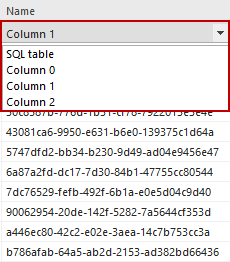
The data source can be changed by selecting another value from the drop down list:
The first item in the list (in the example above – Random generator) represents the default column’s generator which was assigned to the column before mapping. The rest of the items are compatible and parsable (convertible) source columns from the source table.
After refreshing, the data from the new source is loaded and displayed in the preview.
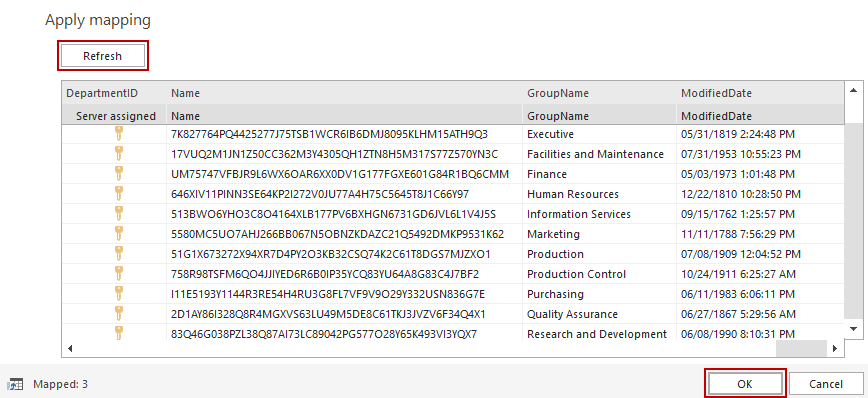
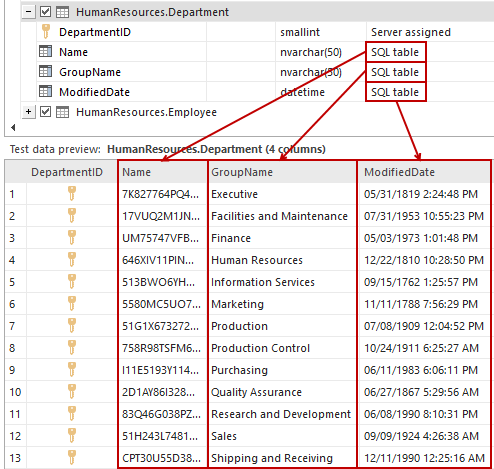
After applying table mapping to the selected table by clicking the OK button, the dialog will close and the new set of generators will be applied to the particular target columns.
Map test data from a CSV file
The first step in mapping from a CSV file is to, like in previous example, load the source file.

When the source file is loaded, data will be presented in the preview grid.
Column names loaded from a CSV file are, by default, formatted with the word Column accompanied with zero-based index (‘’Column 0’’ is first, ‘’Column 1’’ is second, and so on). If the first row in loaded data represent the column’s header, it can be excluded by checking the Use first row as column name option.
Like in mapping from an SQL table, source can be changed by selecting another item from drop down list.
Mapping will be applied after selecting the OK button.
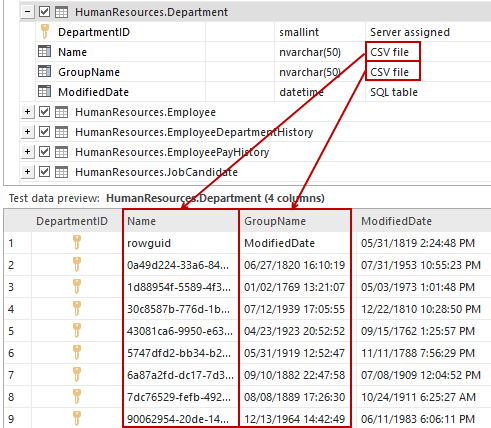
Table mapping in ApexSQL Generate FAQs
-
Q: Which tables/columns support table mapping?
A: Table mapping can be applied to any SQL table, but some columns may not support this feature. Columns that do not support table mapping are server assigned columns, i.e. identity columns, timestamp, computed columns and foreign key columns.
-
Q: What could I use table mapping for?
A: Besides importing large or small amount of data from an external sources, table mapping can be used for preserving original data for specific columns and generating new test data for other.
-
Q: What are “compatible columns”?
A: Compatible columns are columns that share the same data type.
-
Q: What are “convertible columns”?
A: Convertible or parsable columns are columns whose data can be parsed into another column’s data type.
For instance, if the target column is of a string type (nvarchar), data from source column can be of any type (numeric, datetime, image, etc.) if the precision of the target column’s data type is greater that data from source. If the target data type is nvarchar(3), data from source, e.g. integers, can be parsed to string, but precision of source column’s data type will allow only numbers with 3 or less digits. Target columns with integer data type can only be mapped to the same or smaller types, e.g. Int32 (int) can be mapped to int, smallint (Int16) or tinyint (Byte) but cannot be mapped to bigint (Int64).
-
Q: Is it possible to modify applied settings at a column level later?
A: Yes. After applying mapping to a table, a new generator (CSV or Table, based on mapping type) is assigned to the particular columns and its settings can be modified for each column separately by selecting column in treeview, or the mapping can be overridden by selecting any other generator type.