
Applies to
ApexSQL Refactor
Summary
This article explains how to set the options in the Split table refactoring method on SQL Server, using ApexSQL Refactor, to gain the best performance based on needs.
Description
Moving and copying columns and creating a foreign key relationship
When splitting a SQL Server table, the primary, and the secondary table need to have at least one column in common. Otherwise,when trying to open the script or the Preview button is clicked, the following message will be prompted:
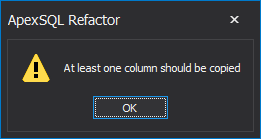
This column(s) is required for vertical partitioning, because it is the basis for linking the two tables and creating a primary key on a secondary table.
|
Quick tip: Do not copy NULL columns because a primary key cannot contain NULL. If a copied column allows NULLs it will be modified to disallow NULLs when the refactoring script is executed |
In a relationship between tables the “parent” table has a primary key column or columns that uniquely identify each row, and the “child” table has a foreign key column or columns, that must be populated with values that are the same as existing value(s) of the primary key in the parent table.
ApexSQL Refactor offers a choice whether to create a foreign key on a primary or a secondary SQL Server table. Since at least one column from a primary table has to be copied, depending on a column copied from a primary table and a relationship that’s created a foreign key relationship is set.
A one to many (1:M) relationship
In a one-to-many relationship, each row in the primary table can be related to many rows in the secondary table.
Let’s consider an example of the Employee table that represents basic information about an employee:
CREATE TABLE Employee ( EmployeeID INT NOT NULL IDENTITY(1, 1) CONSTRAINT [PK_EmployeeID] PRIMARY KEY CLUSTERED , FirstName NVARCHAR(50) NOT NULL , LastName NVARCHAR(50) NOT NULL , Email NVARCHAR(50) NOT NULL , BirthDate datetime NOT NULL, )
Assuming that an employee can have more than one email address, the Employee table will be split into two. The secondary table EmployeeEmails will include the Email column and reference the EmployeeID column. A created 1:M relationship assumes that an email address is used only by one employee, and an employee may have several email addresses.
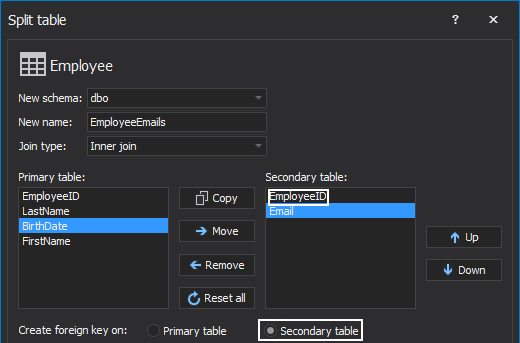
In a 1:M relationship a foreign key should be an attribute (column or columns) in the secondary table that can repeat. Here is the created foreign key on the secondary table:
-- Create Foreign Key FK_EmployeeEmails_Employee On EmployeeEmails ALTER TABLE [dbo].[EmployeeEmails] WITH CHECK ADD CONSTRAINT [FK_EmployeeEmails_Employee] FOREIGN KEY ([EmployeeID]) REFERENCES [dbo].[Employee] ([EmployeeID]) ALTER TABLE [dbo].[EmployeeEmails] CHECK CONSTRAINT [FK_EmployeeEmails_Employee] GO
A one to one (1:1) relationship
A common reason for partitioning a SQL Server table to make 1:1 relationship is if a few of the table columns need to be accessed significantly more often than the rest of the columns. In this case let’s consider an example of the Employee table that beside the basic information about an employee also includes the EvaluationDescription and the EvaluationNumber columns:
CREATE TABLE Employee ( EmployeeID INT NOT NULL IDENTITY(1, 1) CONSTRAINT [PK_EmployeeID] PRIMARY KEY CLUSTERED , FirstName NVARCHAR(50) NOT NULL , LastName NVARCHAR(50) NOT NULL , Email NVARCHAR(50) NOT NULL , BirthDate datetime NOT NULL , EvaluationDescription varchar (max) NOT NULL , EvaluationNumber UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL, )
Assuming that those columns are accessed once in a month (or once a year), split the Employee table into two tables and leave only basic employee info in the primary table. The secondary table, EmployeeEvaluations will contain the less frequently accessed columns: EvaluationDescription and EvaluationNumber.
In a 1:1 relationship a foreign key should itself be a primary key in the secondary table that guarantees that there can be at most one row in the secondary table with that value and a foreign key is on the primary table:
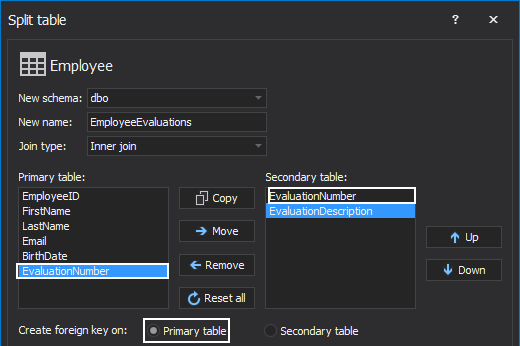
Here is the foreign key created on a primary SQL Server table:
-- Create Foreign Key FK_Employee_EmployeeEvaluations On Employee ALTER TABLE [dbo].[Employee] WITH CHECK ADD CONSTRAINT [FK_Employee_EmployeeEvaluations] FOREIGN KEY ([EvaluationNumber]) REFERENCES [dbo].[EmployeeEvaluations] ([EvaluationNumber]) ALTER TABLE [dbo].[Employee] CHECK CONSTRAINT [FK_Employee_EmployeeEvaluations] GO
In the above example, the EvaluationNumber column is chosen as a UNIQUEIDENTIFIER to be a primary key. However, if such column is not available, the EmployeeID column can be copied in the secondary table:
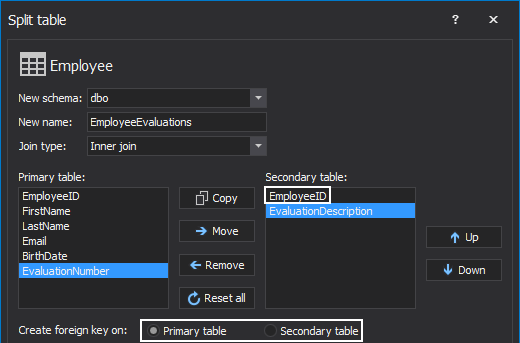
In this case based on the columns that are selected both 1:M, M:1 and 1:1 relationships can be set.
Choosing the right JOIN type
ApexSQL Refactor offers three types of JOIN statements, INNER JOIN, LEFT OUTER JOIN and, RIGHT OUTER JOIN, to choose for merging primary and secondary tables after refactoring in all dependent objects:
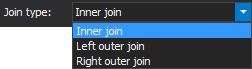
Depending on a reason for a split a few simple examples of most common scenarios in vertical partitioning with results produced by different join types will be shown.
Retrieving all columns from a table
In case of a 1:M relationship example, let’s suppose there is a view that pools all columns from the Employee table:
CREATE VIEW [dbo].[vEmployee] AS SELECT * FROM [dbo].[Employee]
After splitting the table the view and choosing the INNER JOIN as a join type will be refactored also:
CREATE VIEW [dbo].[vEmployee] AS SELECT * FROM (SELECT main_source.EmployeeID, main_source.FirstName, main_source.LastName, source.Email, main_source.BirthDate FROM [dbo].[Employee] AS main_source INNER JOIN [dbo].[EmployeeEmail] AS source ON source.EmployeeID = main_source.EmployeeID) e GO
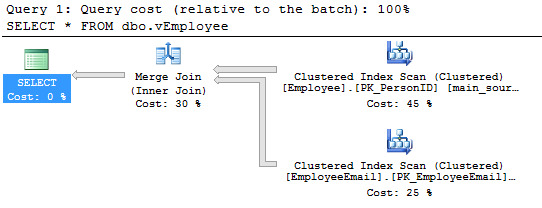
Running the [dbo].[vEmployee] view gives the following results:
SET STATISTICS IO ON SELECT * FROM dbo.vEmployee SET STATISTICS IO OFF
![Dialog showing the results of running the [dbo].[vEmployee] view gives](/wp-content/uploads/2014/05/RowsAffected.png)
If the LEFT OUTER JOIN is used, the vEmployee view would be refactored as:
CREATE VIEW [dbo].[vEmployee] AS SELECT * FROM (SELECT main_source.EmployeeID, main_source.FirstName, main_source.LastName, source.Email, main_source.BirthDate FROM [dbo].[Employee] AS main_source LEFT OUTER JOIN [dbo].[EmployeeEmail] AS source ON source.EmployeeID = main_source.EmployeeID) e GO
Running the view using LEFT OUTER JOIN gives the same result as the view with INNER JOIN:

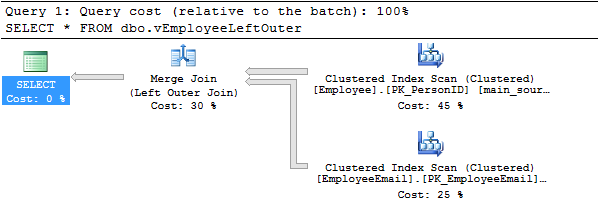
Using the RIGHT OUTER JOIN:
CREATE VIEW [dbo].[vEmployee] AS SELECT * FROM (SELECT main_source.EmployeeID, main_source.FirstName, main_source.LastName, source.Email, main_source.BirthDate FROM [dbo].[Employee] AS main_source RIGHT OUTER JOIN [dbo].[EmployeeEmail] AS source ON source.EmployeeID = main_source.EmployeeID) e GO
The results of executing the view with RIGHT OUTER JOIN are the same as in the previous two examples:


In the execution plan of the above example the operator Merge Join (Left Outer Join) is the same as the one when left outer join is used. This is because SQL Server usually tries to avoid right outer join and it requires special circumstances to come across one.
In this case SQL Server assumed that it is better to execute left outer join and switch the table order than to execute a right outer join.
In the case of retrieving all columns from the Employee table the execution plan and SET STATISTICS IO shows the same results in all three join types.
Retrieving only columns from the primary table
In the example of creating 1:1 relationship, a table is split because some columns are accessed rarer than columns left in a primary table. In those cases majority of IO requests will be for retrieving columns from a primary table:
SELECT [EmployeeID], [FirstName], [LastName], [BirthDate] FROM [dbo].[vEmployee]
Results of the query on this view using INNER JOIN will be:
SET STATISTICS IO ON SELECT [EmployeeID], [FirstName], [LastName], [BirthDate] FROM [dbo].[vEmployee] GO SET STATISTICS IO OFF
![Results of the query on the [dbo].[vEmployee] view using INNER JOIN](/wp-content/uploads/2014/05/RowsAffectedIII.png)

In this case using LEFT OUTER JOIN will give better results because it will scan only the primary table:


The results of executing the view with RIGHT OUTER JOIN again showed that SQL Server executed left outer join, but scanned both tables:
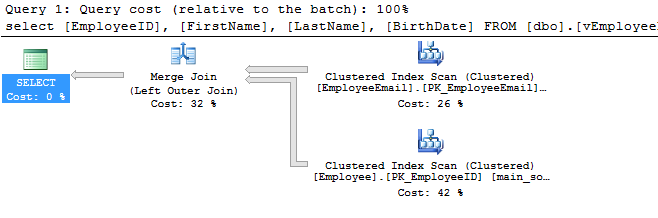
In the case of retrieving only columns from the primary table the execution plan and SET STATISTICS IO shows the best results for left outer join type.
Useful links:
Relations
Introduction to Joins
Merge Join